
Table of contents
Enterprise Search enables a single user to retrieve content across multiple, disparate systems such as Google Drive, SharePoint, Notion, Microsoft Teams, Confluence, Box, Salesforce, Workday, ServiceNow, and other applications. From our Introduction to Moveworks Enterprise Search blog, we discussed that a key challenge for building an enterprise-wide search solution is permissions, respecting and enforcing them across many different content systems – and then doing this at scale.
However, building search permissions correctly means overcoming numerous technical and security challenges to ensure the right information is securely surfaced to the right parties at the right time. In this article, I will share why and how we built our system in this way.
Permissions platform: Technical requirements
Within enterprise search, systems can have two main types of integrations - mirroring or live API. Mirroring is the process of replicating data, e.g. HTML knowledge articles, permissions, etc, through an API onto another platform. The benefits of mirroring is that content can be normalized and optimized within an index for great search performance.
On the other hand, live API refers to impersonating the user and sending the query to the system’s search API to retrieve permissioned results. The benefits of live API is a faster integration for enterprise search; however, solely relying on live API implementation will lead to varying retrieval quality because the search API is different across systems. This will create a negative impact on the end user experience.
Some systems, such as Google Drive or Confluence, offer both types of integrations; whereas other systems, such as Sharepoint On-Prem or Notion, do not offer a permissions API endpoint and restrict to only a live API integration. This reality underscores the complex landscape of systems, emphasizing the importance of building an effective permissions platform that adheres to these specific requirements:
Integrates seamlessly irrespective of the permissions implementation, such as mirroring or live check permissions, to delegate authentication (e.g. allow a third party to manage the authentication process for a user) and access the data. As a result, systems like Google Drive via mirroring or Notion via live check can be enabled via permissions.
Normalizes the data from different permission models, including Role-based Access Control (RBAC), Attribute-Based Access Control (ABAC), or Relationship-Based Access Control (ReBAC), across all the content systems for fast processing during evaluation.
Enforces the permissions, based on the user and resource, and can incorporate custom domain-specific language (DSL) written by administrators for tailored enforcement of permissions.
Provides transparency to administrators, who need visibility into the access decisions being made in the permissions platform with corresponding audit logs.
Why search permissions are challenging
While we’ve discussed the requirements, scaling the system is no trivial task. Scaling here means handling more customers, integrating with additional content systems, managing an ever-increasing volume of content, supporting larger user bases, and making a high volume of real-time access decisions.
There are key challenges in scaling an enterprise permissions infrastructure in order to maintain low-latency decision making, in the order of sub-milliseconds, for a great end user experience:
- Frequent permission updates: On the aggregate, personal documents, such as a shared google doc, have frequent permission updates that need to be mirrored and ingested quickly. This issue exacerbates when the content system does not have APIs to provide incremental updates to quickly mirror the changes within the search index.
- Large data volume: The platform needs efficient storage mechanisms for permissions to ensure quick data retrieval for search. For example, membership for each Sharepoint group has been found to have hundreds of thousands of users for large enterprises.
- Concurrent enforcement calls: Thousands of users are querying the enterprise search solution, in which each retrieval call would toggle many resources - users, groups, group membership - to evaluate the permissions and determine what can be served to each individual user.
- Provide real-time auditing: Providing transparency to administrators for a high volume of content, with frequent permissions changes, occurring across many content systems within a given organization is a challenge.
We'll begin by outlining the framework to how we're addressing these requirements, and then in subsequent blogs, we will cover our solutions to the scaling challenges within the permissions platform.
Our approach: Building a unified permissions platform
Creating a fine-grained authorization system demands a scalable, flexible, and centralized approach to managing access control. Google’s Zanzibar, a global, consistent authorization system published in 2019, is a landmark solution in this domain. It powers permissions for Google products like Google Drive and YouTube and uses a relationship-based model that defines permissions based on relationships between users and resources. This approach supports real-time, globally consistent access control, handling complex sharing, and delegation with high efficiency. By modeling permissions as a graph, Zanzibar achieves fast and dynamic scalability, even in large, complex environments.
Inspired by Zanzibar, open-source projects like OpenFGA and SpiceDB provide similar relationship-based models for fine-grained authorization. These implementations, along with Zanzibar itself, emphasize a centralized system with clear management of core concepts, a single source of truth, and precise points for decision-making and enforcement.
To build an effective authorization infrastructure, there are four foundational pillars:
Point of configuration: The central repository for policy definitions, ensuring policies can be updated in real-time and consumed consistently, irrespective of the system’s permissions implementation approach.
Point of data: The core data store where access rights, relationships, roles, and other permissions data are centralized. Put another way, this is where the various permissions systems are normalized.
Point of decision: The decision engine that interprets policies and determines whether access should be allowed or denied.
Point of enforcement: The layer where access control is applied, ensuring that only authorized users gain access to resources and provides transparency of the decision-making via audit logs.
These pillars collectively provide a unified, high-performance framework for managing complex permissions at enterprise scale. In the next section we will dive into each pillar and how they collectively support a secure, unified permissions framework.
Core pillars of a unified permissions platform
1. Point of configuration
At the heart of a robust permissions system are policies expressed as configurations within our centralized config management infrastructure. These policies are accessible to clients in near real time, meaning that as changes are made, they can be immediately reflected on the client side without requiring extra network or I/O calls. This centralized configuration infrastructure offers several advantages: reliability, low-latency reads, consistent policies, built-in auditability, and the ability to roll back policy changes as needed.
Our internal configuration platform allows us to manage policies seamlessly, ensuring secure, responsive, and consistent permissions management across the organization.
2. Point of data
While policies define strategies to protect content, data controls are put in place at the record level. The central permissions store acts as the “Point of Data,” applying fine-grained authorization to each enterprise data record. This store can be populated with data synced from external systems or created and managed by organizations.
To support relationship-based access control (ReBAC), the permissions data typically includes relationships, roles, groups, and group memberships. The store’s design is generic and agnostic to any specific system, allowing it to adapt to diverse use cases seamlessly. Permissions data is represented in a general tuple structure that defines the relationship between objects and users. Regardless of data origin or the access control model (e.g., ReBAC, RBAC), all relevant permissions data is housed within this core storage structure.
To accommodate variations across systems, query data models are layered on top of this core structure. Minor differences between systems are normalized within a general query model, which works for most standard permissions systems. For more complex systems, where permissions evaluation requires hierarchical queries, a specialized query model is used to handle these advanced requirements efficiently. This flexibility allows the permissions store to integrate seamlessly with a wide range of external systems and permissions configurations.
3. Point of decision
Once configuration and data are centralized, the next critical component in an enterprise permissions infrastructure is centralized decision-making. Regardless of the customer, use case, or resource type, access decisions need to happen in a single place. For every request asking, "Does user X have Y access on record Z?", the system must respond consistently with a definitive allow or deny.
Given the volume of access decisions—often millions per day—ensuring the system is auditable and explainable is crucial for maintaining scale. Each decision not only needs to be accurate but also trackable and understandable, providing transparency into why access was granted or denied.
The platform also needs to support simultaneous decision-making across multiple independent resources, making concurrent decisions for each. For every resource, the system applies the relevant policy, consults the central permissions store for the necessary data, and decides on access rights.
Obtaining permissions data based on policy type
The method for retrieving permissions data in an authorization system varies depending on the policy type:
- Relationship-Based Access Control (ReBAC): The system references a mirrored permissions store, where relationships between users and resources are maintained to allow or deny access efficiently.
- Attribute-Based Access Control (ABAC): The system consults the central configuration infrastructure to retrieve the relevant rule, enabling it to evaluate attributes specific to each request.
- Live Permissions: For permissions that need real-time validation, the system leverages a dedicated subcomponent called Airlock. Airlock securely queries external systems on-the-fly to assess permissions in real time, ensuring that the most current access data is used.
This structure allows the platform to accommodate a variety of access control models, adapting to different enterprise requirements while maintaining a streamlined, centralized process for retrieving permissions data. This unified decision-making framework helps to provide consistency, transparency, and scale in enforcing enterprise-level access control across diverse scenarios.
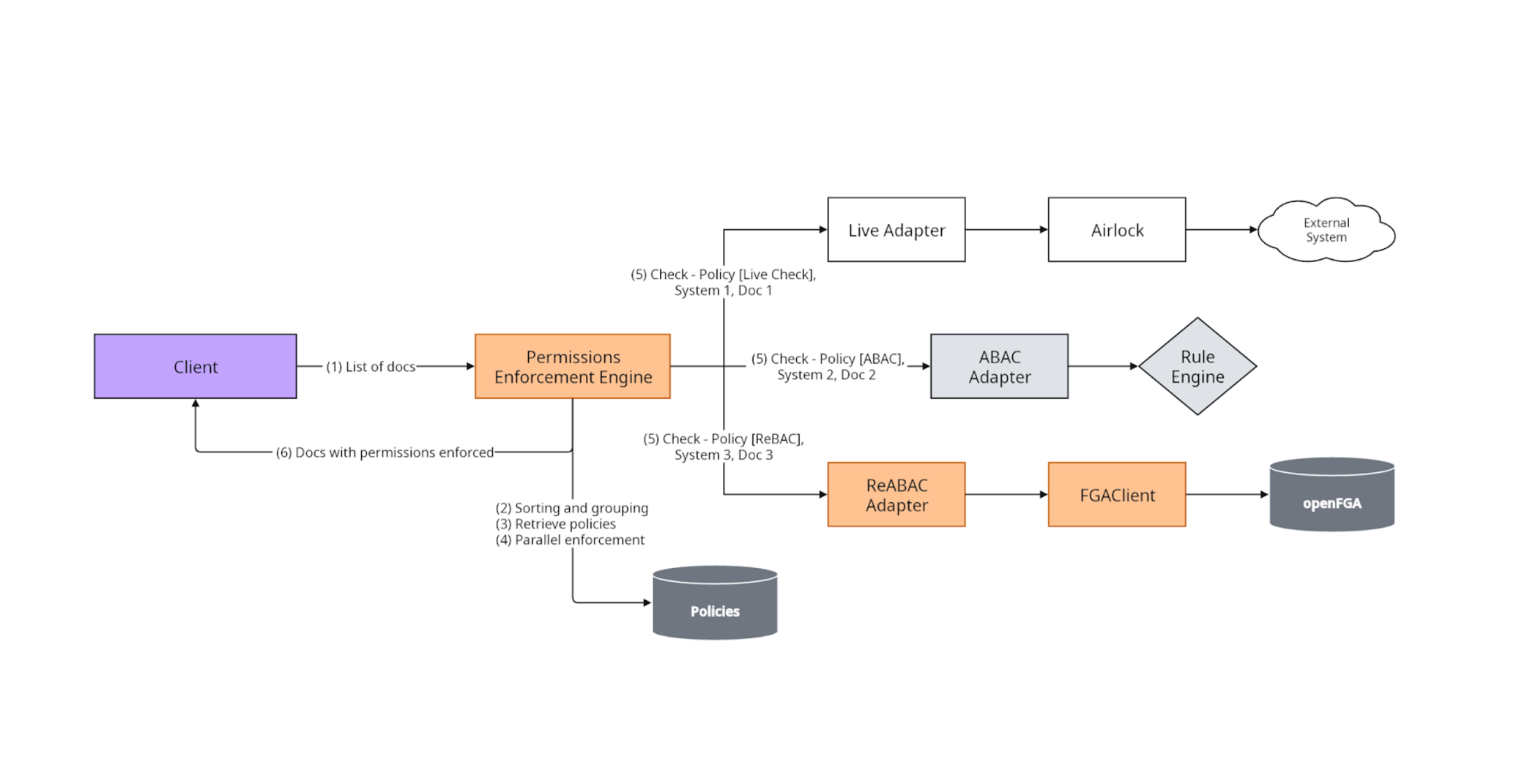
4. Point of enforcement
Identifying the right point of enforcement is crucial for enabling data to remain protected and that necessary permissions are applied before clients can access any information. The specific enforcement location may vary depending on the product being developed, but it is essential that enforcement occurs consistently and in a non-intrusive manner.
One effective strategy is to push enforcement down to the storage layer or to a layer directly above it. This approach makes it possible for access controls to be applied during the query phase (pre-filtering) and/or as part of the filtering process after data retrieval (post-filtering). Whether to implement pre-filtering or post-filtering can depend on the specific policies configured for the resource and the applicable permissions query model.
By helping to establish a single point of entry for all clients accessing content, organizations can better ensure robust and foolproof enforcement of permissions. This architecture not only supports protecting sensitive data, but also simplifies the enforcement process, providing a seamless experience for users while making it possible to maintain strict compliance with access control policies.
Results of building a unified permissions platform
This architecture ensures secure, permission-enforced search by applying multiple layers of access control, from pre-filtering index content based on user permissions to real-time post-filtering with ReBAC, ABAC, and live checks. Live API search and asynchronous search retrieval enables seamless, secure access to authorized content across systems, while an offline permissions pipeline maintains near real-time data consistency. The diagram below illustrates how all these different components come together to build a unified permissions platform.
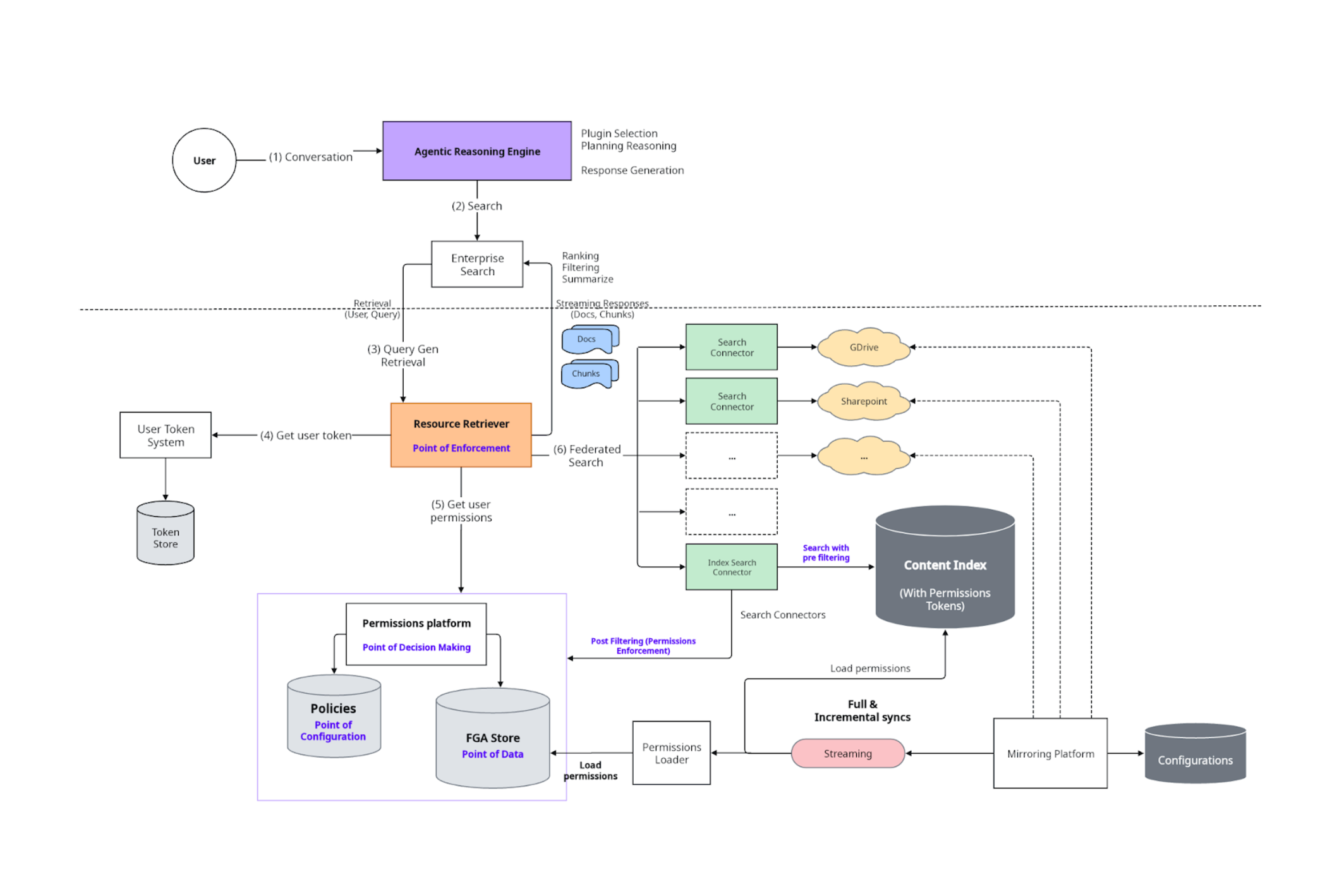
By adhering to the requirements and adopting a layered, secure architecture, our approach delivers a robust and scalable solution that enables the following benefits:
1. Integrates seamlessly irrespective of the permissions implementation:
- Near real-time permissions pipeline: The offline permissions pipeline operates as a streaming system, updating permissions in near real-time to reflect any changes in external systems.
- Provides OAuth protection for external content: Content retrieved directly from external systems is protected by the user’s OAuth token, obtained through explicit user consent and authorization.
2. Normalizes the data from different permission models:
- Centralized permissions platform: The architecture supports mirroring permissions from external systems to a central permissions platform, serving as the single source of truth for permissions and enabling pre-filtering in the content index.
3. Enforces the permissions, based on the user and resource:
- Pre-filtered index content: Content pulled from the index is pre-filtered based on the user’s permissions, ensuring that only relevant information leaves the index.
- Post-filtered by permissions engine: The permissions enforcement layer applies post-filters based on ReBAC, ABAC, and live permission checks, further refining access.
- User-specific content visibility: Access is tailored so that users can view only the data they’re explicitly authorized to see, supported by multiple layers of security.
4. Provides transparency to administrators:
- These components of the system ensure that access decisions are centralized and trackable. Also, they serve as junction points where transparency into access decisions can be practically implemented and create detailed audit logs.
This layered, secure architecture supports search results that are more accurate, relevant, and securely filtered for each user in real-time.
Experience the power of using permissions for enterprise search
Building a permissions infrastructure for enterprise search is a complex engineering task, and a core focus of our solution. It involves creating a flexible abstraction layer that can handle the diverse permission models across various enterprise content systems, building a scalable system to sync and update permissions data reliably, and ensuring secure, low-latency access for advanced search powered by RAG and agentic reasoning.
Operating this at scale to support hundreds of content systems and millions of permission updates requires a resilient and adaptable architecture, one we are proud to have at Moveworks.
Want to dig into the details even further? In upcoming posts, we'll explore the intricacies of abstraction, modeling, and scaling to meet these challenges.
Discover a search experience that’s purposeful, accurate, and trustworthy. Learn more about Moveworks Enterprise Search.

