Table of contents
Grounding is a fundamental process that enhances LLMs outputs – and without it LLMs are only able to use data that they were trained on to produce answers. However, there are numerous misconceptions about what’s possible with grounding, including the false belief that it can ‘fix’ hallucinations.
At Moveworks, we wanted to share our experience with grounding, explore the nuances and capacities of grounding, its relationship to AI hallucinations, and explain why grounding is a critical component of Agentic AI and AI agents.
What is grounding?
Grounding refers to the process of producing text from generative large language models (LLMs) using content and references specific to the query or use case. Without grounding, LLMs are only able to use data that they were trained on to answer questions. The scale of this training data is huge; billions of documents of all types are used in the training process. However, this data has limitations in terms of answering questions that require accurate and authoritative responses:
- The data is a static snapshot that only contains information that was true on the cutoff date.
- There are no guarantees on the accuracy or reliability of the training data because the corpus may have inaccurate or mutually conflicting sources.
- Even when the data is accurate for certain scenarios, it may not be applicable for all scenarios, e.g. a given document about troubleshooting a VPN issue is likely to not be universally applicable given the unique setups that various organizations may have.
Grounding is most frequently done using retrieval augmented generation (RAG) to provide the LLM with content that it is instructed to use during response generation. In this architecture, an LLM is connected to a vector-embeddings based retrieval system connected to a data source, or directly to a set of documents, and exposed to the user through a chat interface. The user can then query the underlying sources, and the RAG system provides summaries that are grounded in retrieved data.
This provided many enterprises their first glimpse of effective search in the era of LLMs. RAG made it easy for enterprises to prototype search applications internally.
The improvement in quality of coherence and relevance of search results was dramatic over prior keyword-based retrieval systems, which provided a wall of (mostly irrelevant and inscrutable) blue links.
Can grounding prevent hallucinations?
Hallucinations are an inherent property of LLMs. When an LLM is asked to summarize content, it can make up information or distort facts to appear coherent and persuasive. The superpower of LLMs is natural and realistic language generation, but it is also their Achilles heel if not addressed properly.
So does grounding LLM responses with relevant resources eliminate hallucinations? The answer is that grounding is necessary, but nowhere near sufficient to prevent hallucinations. Grounding alone cannot overcome the limitation that RAG systems don’t have any architectural capabilities that can impose truthfulness in their results.
There are several causes that can lead to hallucinations even with grounding:
- Poor relevance of retrieved data provided as context: This is a common issue when the content retrieval provides information that is low relevance to begin with. A notable example is keyword-based retrieval, which only returns articles with matching keywords. This may fail completely in situations where:
- The query and content don’t use the same terminology, e.g. if the query is about VPN, but the content only references GlobalProtect, which is a VPN application, then basic keyword matching cannot connect the two.
- When there is a frequently used keyword that can be found in a wide variety of content and topics, e.g. revenue is a term used frequently in all sources such as emails, Slack threads, documents and slide decks. A basic keyword match can return a large number of results, most of which can not be relevant to every query.
- Mutual conflicts among provided data sources: When content is sourced from a range of repositories, there can be real or apparent conflicts between the sources, which forces the LLM to combine them into a single answer, leading to incorrect or inconsistent claims.
- Lack of ability to exercise judgment about which data sources are more reliable: A rudimentary grounded system has no concept of authoritative sources, which leads it to make a naive attempt to summarize all provided information, instead of prioritizing some systems or content. As an example, Salesforce would be considered by the vast majority of sales professionals as being the definitive source for revenue data, but a RAG system does not have this judgment.
- Inability to calibrate and adapt responses based on confidence in results: A basic RAG system does not have the ability to estimate or evaluate how much confidence to ascribe to a particular provided resource. It naively tries to treat all documents the same, which inevitably leads to situations where mutually conflicting information can arise. This can be mitigated by knowing and incorporating relevance scores for resources to determine what to prioritize, but basic RAG does not have this. What’s more, this also prevents the system from conveying its own level of confidence in its answer, projecting a false confidence even when the data does not merit that.
- Excessive context provided to models leading to increased likelihood of confusion: Today, LLMs can take a very large amount of context (GPT-4o has a context window of 128000 tokens, which is roughly 96000 words!) as input, making it possible to provide many documents in one go. However, as the context size increases, the burden of parsing and using the text in a coherent summary also increases. This makes it more likely that the model might get confused and mix up content from different documents, leading it down a path of erroneous conclusions.
- Lack of clarity in prompts: Prompting is an extremely powerful and malleable way to get LLMs to perform tasks as per the user’s specifications. However, prompts can often be unintentionally vague or may contain mutually conflicting instructions, which can cause models to get confused and produce unreliable results. As an example, “Respond to this question in a formal tone, similar to a consulting report,” can cause a model to interpret terms such as formal and consulting and inadvertently trigger generation patterns that are unintended.
- Ambiguity in provided sources leading to misinterpretation: Often, the provided sources are on the topic of the query, but do not have relevant information to answer specific queries. As an example, “Can I wear torn jeans to work?” may be a question that is not addressed by the employee code of conduct, but in many cases, the LLM could make up an answer to fill the gap due to missing information.
- Inability to synthesize and apply logical relationships: LLMs are token generators that inherently do not have the ability to do mathematical or logical operations. Their training data may have incorporated some such sources, but that does not guarantee generalized mathematical ability. A simple example can be asking for the median sales figures based on a provided document that contains sales data for every month. However, since the LLM does not have the ability to do math, it may hallucinate the median.
To summarize, RAG systems can be persuasive in their AI-generated summaries, but can also distort information and potentially mislead their users.
Agentic RAG is better equipped to combat hallucinations
Agentic RAG combines the strengths of Retrieval-Augmented Generation and AI Agents to incorporate autonomous reasoning and decision making as part of finding and presenting relevant information. This approach allows for managing complex tasks across diverse and extensive datasets.
Clearly, with the diverse nature of challenges, there is no one-size-fits all approach. That’s why we have developed an architecture that enables a multi-pronged approach to solving the problem of hallucinations. How exactly does it do that?
For every query, an agentic RAG system performs four key steps:
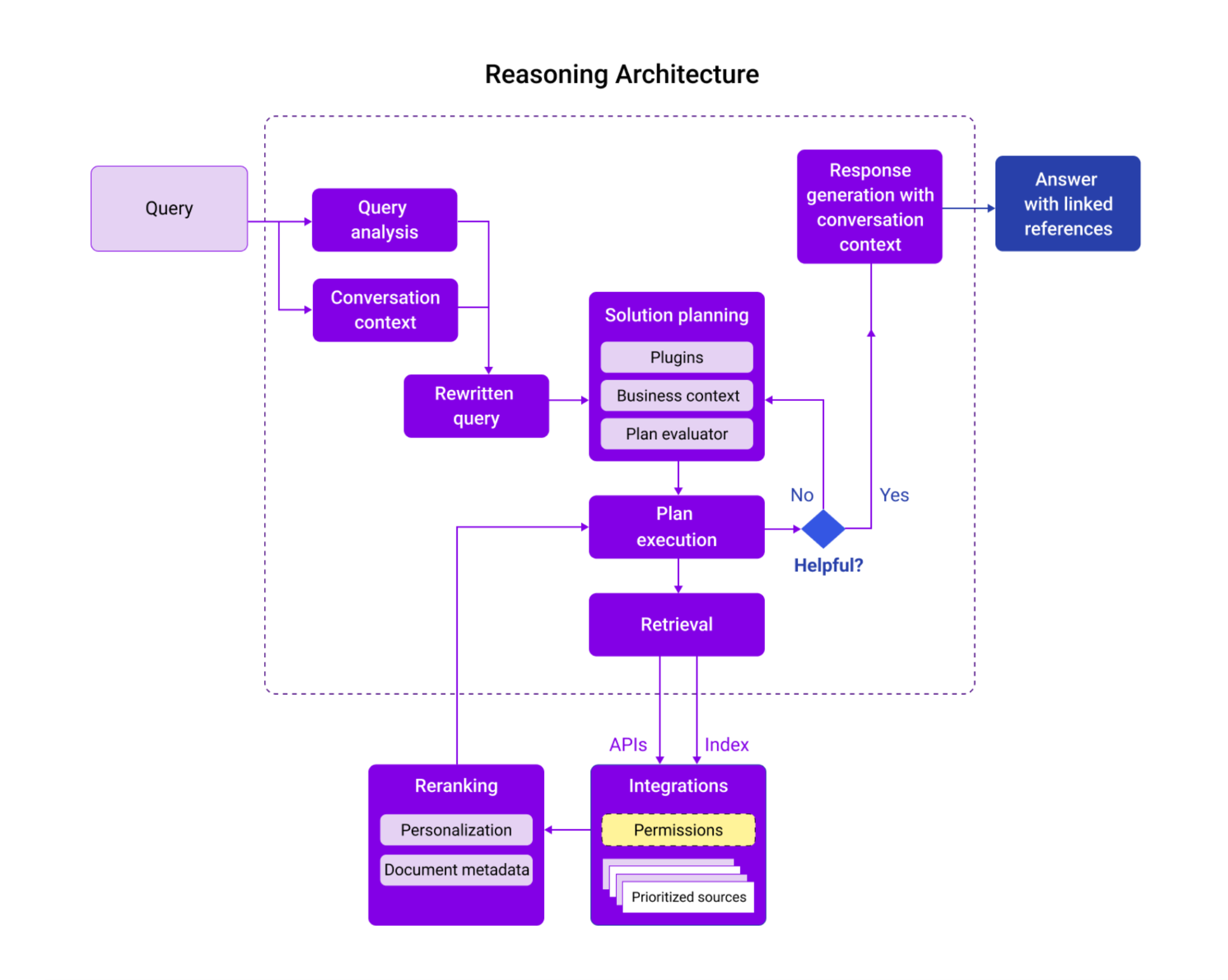
- Addition of business context and organization-specific entities: Moveworks has a rich knowledge graph comprising global and customer-specific entities and the relationships between them, which are injected during the process of query enrichment. These include such diverse entities such as application names, processes, building names, proprietary systems and unique terminology that may be rare or missing in global or common language. This enables the reasoning engine to use the most correct interpretation of an entity and its business context.
- Problems this can address: Ambiguity in provided sources leading to misinterpretation, poor relevance of retrieved data provided as context.
- Addition of conversation context: In conversational scenarios, a significant amount of context exists in prior interactions, which can help expand underspecified or vague queries and prevent presentation of inaccurate or nonsensical results. The reasoning engine applies conversation context to every request and rewrites the query to be better-specified, improving the quality of downstream results.
- Problems this can address: Ambiguity in provided sources leading to misinterpretation, poor relevance of retrieved data provided as context.
- Autonomous reasoning and approach planning: The Moveworks reasoning engine uses an autonomous planning and evaluation module to systematically break down complex requests into smaller sub-tasks, which reduce the ambiguity of the request and the likelihood that there will be incorrect assumptions incorporated implicitly into the response. As it breaks down these requests, it can independently create a plan to use the available tools or plugins in the customer’s environment for each step. Constraining the reasoning engine to invoke specialized plugins dramatically increases the probability that ungrounded or non-referenceable information will make its way into the response. From a trustworthiness perspective, Moveworks provides the user holistic visibility into this planning process with AI reasoning steps at each stage, enabling the user to inspect the query breakdown, all the plugins called and responses received.
- Problems this can address: Inability to synthesize and apply logical relationships, lack of ability to exercise judgment about which data sources are more reliable, lack of clarity in prompts, lack of verifiability.
- Intelligent retrieval and ranking: Moveworks Enterprise Search uses a powerful and versatile retrieval system which uses a range of signals and methods to produce a high-quality ranked list of resources that prioritizes the right mix of systems and content types based on:
- Personalization based on signals such as the user’s role and location
- Prioritization of specific sources for certain queries (e.g. Salesforce is the most reliable source for sales-related queries)
- Incorporate content metadata such as recency and diversity of sources to produce an overall higher quality list of sources
- What’s more, Moveworks is able to rewrite and optimize search requests in multiple ways to get the best possible performance from different API sources, which have widely varying levels of performance based on their ability to process queries. This adds a level of standardization and improves the quality of the results.
- Problems this can address: Poor relevance of retrieved data provided as context, lack of ability to exercise judgment about which data sources are more reliable, excessive context provided to models leading to increased likelihood of confusion, mutual conflicts among provided data sources
- Goal-oriented summarization with linked inline references: Based on the query intent and the ranked results, the summarization autonomously evaluates the utility of results and incorporates the most relevant content and presents them in a concise, easy to consume format. However, unlike naive summarization, Moveworks Enterprise Search takes several critical steps to increase the reliability of the summary:
- The summary takes into account the relevance score of each result found during retrieval, which is key to ensuring that the summarization gets important signals on the reliability of the results, enabling it to weigh those sources appropriately. This is particularly important when summarization is occurring over multiple content types and from a range of sources.
- For every response, Moveworks includes inline references to the source content, enabling the user to independently verify the resources, if they wish.
- We maintain a relevance bar so that if there are no reliable or high confidence results available, Moveworks will inform the user and ask them to rephrase their query. This is key to maintaining rigor in the quality of the results and avoids the problem of over-eager summarization, which occurs when an LLM makes up facts due to a bias towards producing text to comply with the user’s request.
Fact-checking and input/output validation: In addition to all the above, we firmly believe that it’s essential to validate the quality of both inputs and outputs. With this goal, we are developing in-house Fact-Checker models to help verify the accuracy of each response with respect to the sources that it claims to cite. In addition, we also use a custom fine-tuned toxicity check model that detects toxic, unprofessional or problematic inputs and reduces the occurrence of cases where the topic is unsuitable for a work environment, and there is likely no relevant information present. This helps to further reduce the likelihood of hallucinations.
- Problems this can address: Lack of verifiability, poor relevance of retrieved data provided as context.
All of the strategies that referenced above are deeply embedded into our reasoning architecture (graphic below). As you can see, these strategies are made possible with an agentic architecture capable of adapting and deconstructing the query, selecting from multiple tools, planning a multi-step approach, incorporating a variety of contexts and producing responses that are tailored and linked with references. Together, all of these steps are critical to helping to minimize hallucinations and provide a truly grounded experience: This is the power of Agentic RAG in action.
Want to learn more about the power of Enterprise Search? Learn more about our solution at our virtual live event on November 12 at 10AM PT.

