
Table of contents
Enterprise search is critical, especially since organizations have terabytes, even petabytes of data within billions of documents, files, and business systems spread across multiple systems. This setup is justified - every department, team and individual has specialized data needs, workflows, and regulatory requirements that no central tool can capture. For example:
- Large organizations have legacy data systems that were built in-house or purchased years ago. These systems store critical data that is difficult, risky, or costly to migrate.
- Many departments have unique compliance needs - finance departments can only use file systems that are SOX compliant (e.g. Oracle ERP) while healthcare and insurance departments need file systems that are HIPAA-compliant (e.g. Epic or Cerner).
- Organizations have to purchase multiple instances of the same data storage systems to isolate user groups and prevent unauthorized permission sharing.
- Even each employee can have different preferred file storage and note taking applications compared to their peers.
The sheer volume of information hidden in the distributed, maze-like setups has historically meant that most employees were unlikely to find information they needed to be effective. This amount of information was virtually impossible for the average employee to discover because of application silos that each have varying formats and permissions.
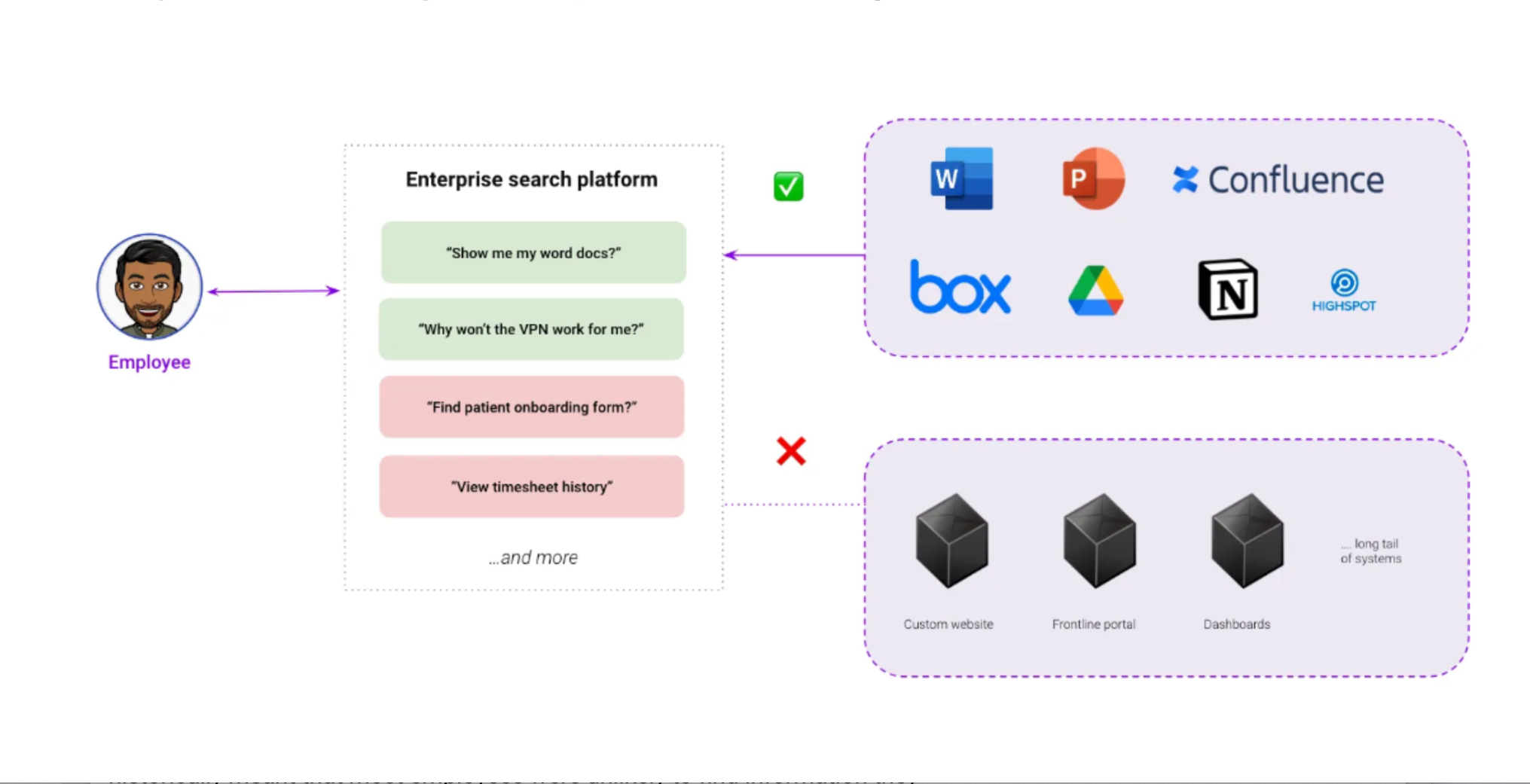
Enterprise Search systems are powerful at helping employees find important information
Employees need an easy, federated way to search and navigate internal information, that allows searching across multiple siloed sources simultaneously. In the last five years, powerful enterprise search systems were born. An effective enterprise search system is:
1. Fully integrated: Connects information from all content management systems
2. Reliable: Retrieves the right documents at the right time
3. Easy-to-use: Provides a simple interface to employees
Unfortunately, enterprise search systems are rarely integrated with all content systems.
Lack of custom integrations and out-of-date information break enterprise search
Most enterprise search systems today have integrations to popular tools like Sharepoint, Google Drive, Confluence – but they often lack integrations to the long tail of business systems. This is essential because not everything can be stored on popular tools, and many additional knowledge systems are required to match your organization’s intricate needs. Let’s take a few examples:
- A home-grown content management system that powers your website
- A custom portal containing operating procedures for all your frontline workers
- A repository of compliance documents that house all your legal policies
- An internal database that stores all your customer engagement insights
Being able to access and understand this knowledge is crucial for your employees. But as soon as knowledge management exits mainstream tools, the ability to leverage enterprise search products is impeded by the lack of data integrations. Enterprise search systems are powerful at helping employees find information, but they don’t always integrate with many crucial systems – resulting in incomplete search results.
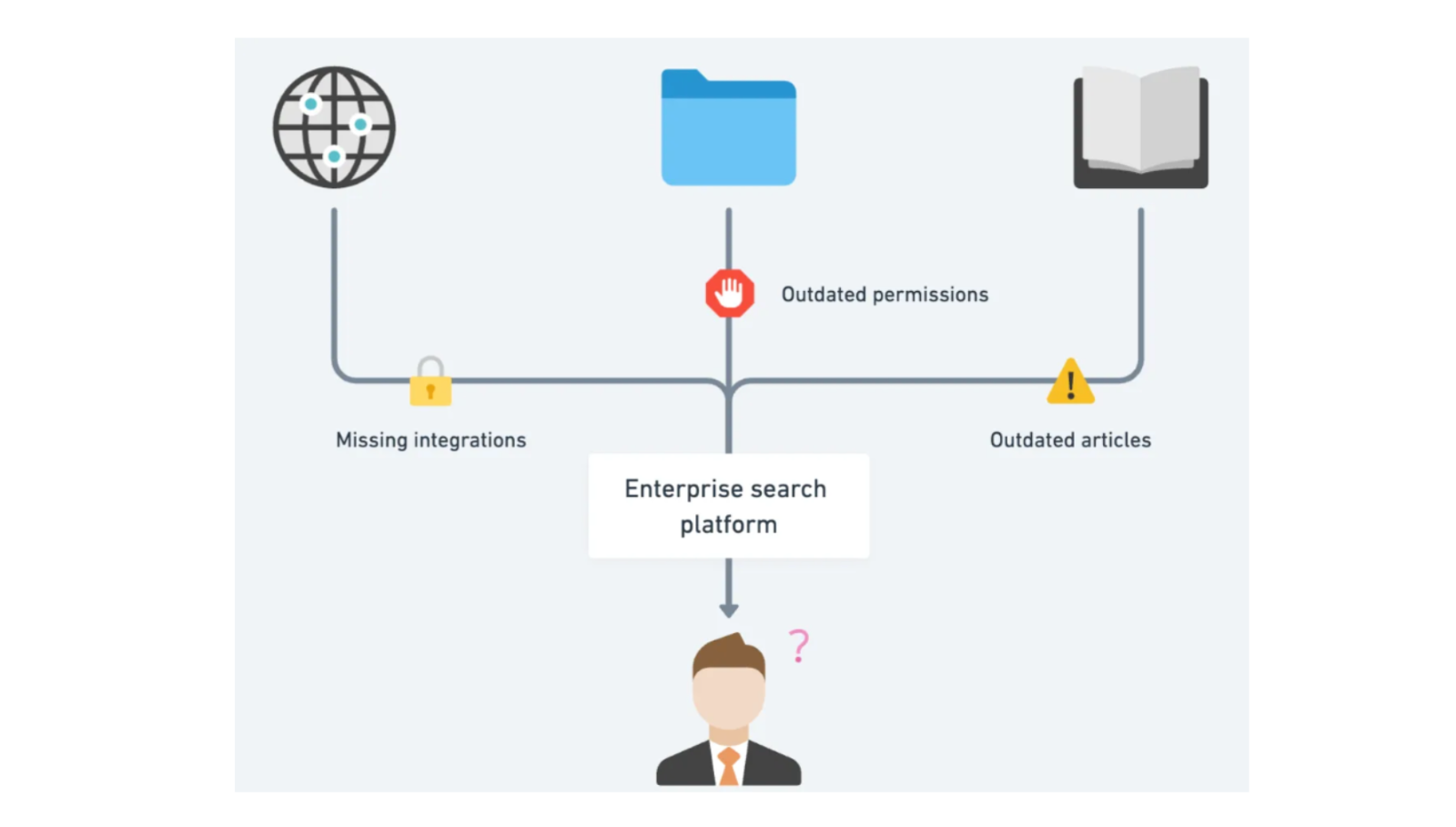
Some organizations try to bypass integrations and upload content on a one-time basis. But one-time content uploads don’t meet organization needs, since content and permissions are ever-evolving. You want to ensure that your users follow the latest policies. You want to make sure that authorized users don’t see policies that they have lost access to. You want your information to be as up-to-date – and as accurate – as possible.
As a result, even with an enterprise search platform, employees may:
- Struggle to find important information because of missing integrations
- Be served info they shouldn’t have access to due to outdated permissions
- Be served outdated, potentially inaccurate info from outdated articles
To keep your enterprise search system in sync with your content system, your organization needs to build your own content integrations.
Data integrations are necessary but challenging and costly to build
Building a content integration is no easy feat for developers and data engineers. Today’s approaches typically require a developer to be responsible for the end-to-end journey of building data pipelines. Developers need to own the following:
Build robust ingestion pipelines: They need to manage polling / scheduling, crawl large pages of API responses (often 1000s of files per integration), handle failures / retries, setup diffing for content changes, and deal with limitations to ingest faster than 24 hours. This setup often requires significant infrastructure overhead and engineering expertise.
Prepare docs for ingestion: This includes groundwork such as: parsing logic for a ton of content types (html, mdx, ppt, pdf, docx, txt, more), making sure responses are trimmed to fit within LLM context limits, snippetizing the content to improve data presentation to users, improving search semantic understanding, and filtering irrelevant content (remove watermarks, lettermarks, headers). Developers often have to purchase and set up heavy “pdf to txt” or “OCR” libraries.
Setup ingestion for complex permissions: You want to make sure users never access a file they shouldn’t have access to. This means ensuring up-to-date or near real-time permissions that support different permission storage models (i.e file-level and folder-level permissions), as well as support for custom permission attributes. Permissions are often distributed across Content, Group and User tables in knowledge systems. Developers need to merge all this data to calculate final permissions and merging tables, which is often an expensive and flaky operation.
Building these data integration pipelines is also often an expensive process. Today, developers are burdened to manage this painful integration setup. An ideal data integration solution should be:
Inexpensive: Low cost for developers to configure and manage
Re-usable: The efforts to configure 1 system <-> search platform integration should be re-usable across integrations.
Scalable: Allow integrating with as many data sources and content types as needed.
Flexible: It should adapt to your permissions and data freshness requirements.
Content Gateway: Help free developers from building data integrations
With Content Gateway, developers require minimal data infrastructures when connecting custom knowledge systems as part of Moveworks Enterprise Search. Content Gateway helps to shift these responsibilities from developers to Moveworks, enabling a reduction in developer burden from building data integrations.
Here’s an overview of how that responsibility gets shifted:
Traditional Content Indexing | Content Gateway | |
1. Periodically retrieve content | Owned by developers | Owned by Moveworks |
2. Crawl retrieved content | Owned by developers | Shared responsibility |
3. Efficiently process changed content | Owned by developers | Shared responsibility |
4. Parse many content types | Owned by developers | Owned by Moveworks |
5. Pre-process content for Copilot Search | Owned by developers | Owned by Moveworks |
6. Index content permissions | Owned by developers | Shared responsibility |
7. Error handling and retry logic | Owned by developers | Owned by Moveworks |
Instead of building complex data pipelines and merging tons of data, Content Gateway empowers developers to build on top of pre-existing APIs that they use for managing content. Moveworks provides simple interfaces for developers to implement APIs that follow standard and re-usable oData practices.
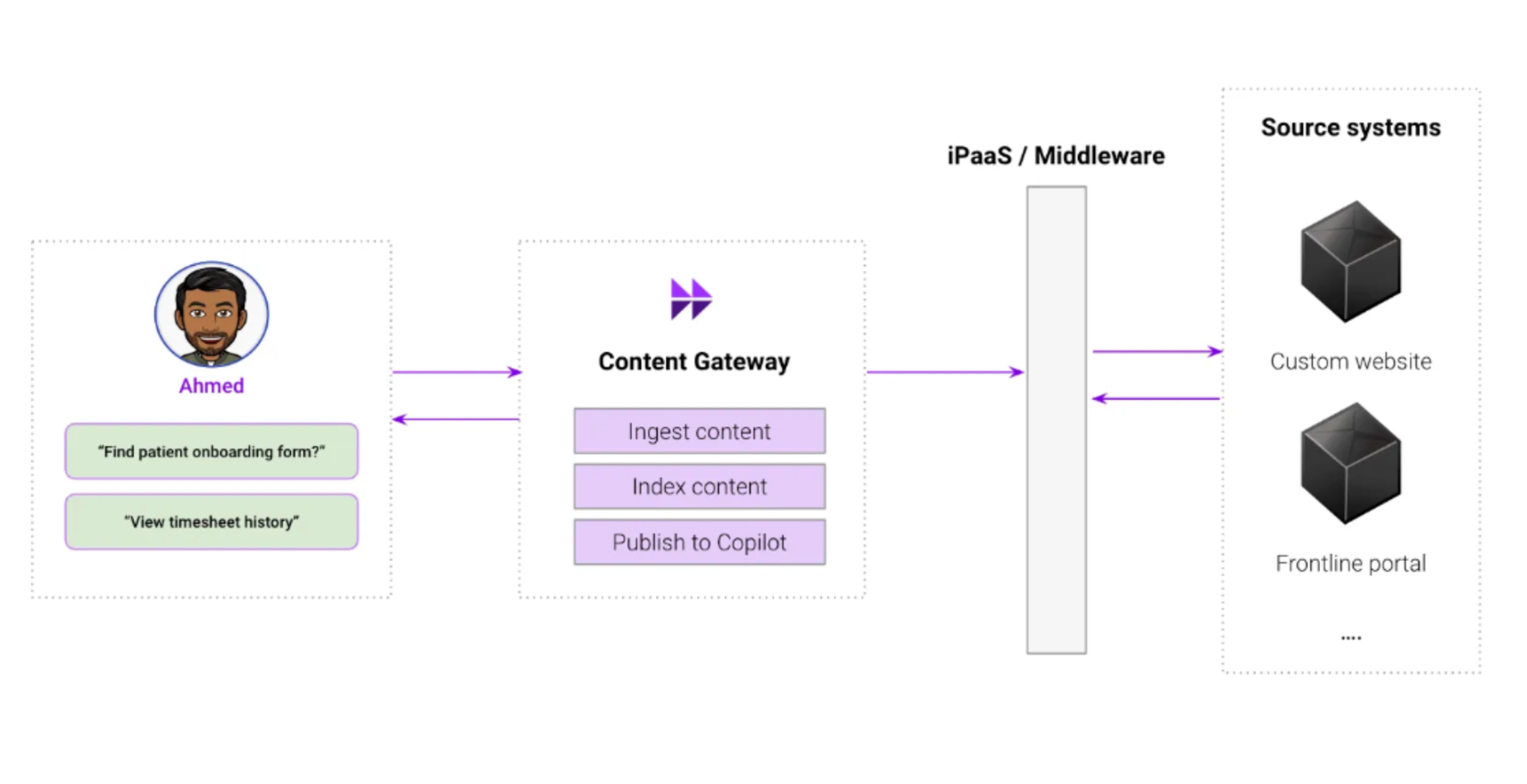
Moveworks then connects to these developer APIs through our enterprise-grade content and data ingestion platform. This data ingestion platform has many key benefits:
End-to-end ingestion pipelines: Moveworks handles ingestion job scheduling, retries and errors, log management, document parsing, snippetization, and indexing. All your developers need to worry about is providing the correct REST APIs. This does require developers to use an orchestration tool.
Near real-time content: Moveworks provides multiple ingestion options. Depending on your need you can set up daily ingestion or ingestion that syncs with your source systems every few minutes. This means ability to keep content and permissions up-to-date and fresh in your enterprise search solution.
Integrated permissions: Content Gateway can support and sync several complex permission types, helping to prevent users from being served content they shouldn’t have access to.
Efficient ingestion: Reduce the burden on content systems by only re-ingesting files that have detected changes. This means faster ingestion that’s more efficient and also less likely to fail.
Support for many content types: Content gateway will support KBAs, PDFs, DOCs, PPTs, TXTs content and more. We plan to further extend this support to more resource types such as identity, users, forms, tickets, custom resources, etc.
We’re excited to launch our content gateway’s first module: Files Gateway, an extensible approach to integrating custom files systems. All your developers need to start is a server or iPaaS to host APIs.
This Content Gateway approach makes it possible for your Copilot to be integrated with bespoke business systems. It enables your employees to be more productive with a search platform that spans across all your systems.
Transform how your team finds answers with a search solution powered by agentic RAG. Discover how Enterprise Search delivers the answers employees need with Moveworks Enterprise Search today.
Ready to get started with Content Gateway? Content Gateway capabilities will be made available to all customers with the Moveworks Enterprise Search platform at no additional cost.

