
Table of contents
Tech headlines are flooded with news about AI on a daily — if not hourly — basis. That’s just a fact.
This trend started in November 2022 when OpenAI released ChatGPT. Practically overnight, AI became a household topic — even though we’ve been using it in tools like Siri for over a decade.
Still, some call this AI boom the biggest tech evolution since the Internet. Even everyday items are getting an AI upgrade: refrigerators that automatically order groceries, fitness equipment that personalizes workouts, predictive text keyboards on our phones, and so much more. AI is unavoidable!
Why? Well, at its core, AI is all about enhancing efficiency and productivity. Whether in our homes or our workplaces, AI systems take care of repetitive tasks, catch mistakes we might miss, and give us more time to focus on the challenging and creative parts of our work and lives.
It’s no wonder why AI has become so attractive to businesses of all sizes. Companies are eager to harness AI's power to drive efficiency. Every organization is evaluating where it can streamline processes and boost productivity, especially as we all experience economic challenges.
Among AI technologies, large language models (LLMs) stand out as particularly promising for enterprise applications. However, to fully capitalize on their potential, we must first understand how to effectively deploy LLMs in business settings. This blog aims to provide a quick overview of leveraging LLMs in enterprise settings by exploring:
- Need-to-know terminology
- Types of LLM deployments in enterprise settings
- How Moveworks fits into the equation
Key enterprise AI terms
Before we discuss main types of enterprise LLM deployments, it’s important to ground ourselves on some of the common AI terms.
Generative artificial intelligence (GenAI)
Generative AI refers to artificial intelligence systems that can create new content, such as text, audio, images, or video, in response to user input. These systems are built on large models trained on vast datasets, allowing them to understand patterns and generate human-like outputs.
In the context of this blog, we focus specifically on text-based generative AI powered by large language models (LLMs). These LLMs can understand and produce human-like text, enabling a wide range of applications from answering questions to writing content.
Large language models (LLMs)
Large language models (LLMs) are a type of deep learning model trained on a large dataset to perform natural language understanding and generation tasks. They understand and generate content using natural language processing (NLP). This results in more conversational outputs.
Retrieval-augmented generation (RAG)
RAG is a generative AI method that retrieves relevant information from a large, regularly updated knowledge base to generate natural language responses. It compiles information from multiple sources and combines it with the prompt or question to create or generate a response/output.
In short, retrieval-augmented generation (RAG) follows the following steps.
Prompt with question
Retrieve information from source
Combine with user questions
Generate a response
Note that simply retrieving information from some source and using it to generate a response alone does not guarantee relevance or accuracy of the response. For RAG to be an effective mechanism to answer questions, the information retrieved must be relevant and correct.
 Figure 1: Retrieval-augmented generation (RAG) retrieves relevant information from a large, up-to-date knowledge base and combines it with the prompt to generate natural language responses.
Figure 1: Retrieval-augmented generation (RAG) retrieves relevant information from a large, up-to-date knowledge base and combines it with the prompt to generate natural language responses.
Prompting
Prompting is how users interact with generative AI by providing instructions, questions, or queries to achieve a desired result.
Grounding
Grounding is the ability to connect or reference generative AI outputs to verifiable or cited data sources. This technique anchors a model to specific information, increasing the validity of the generated output. Grounding makes AI systems more context-aware, enabling them to provide more accurate, relevant, and relatable responses or actions.
Hallucination
Hallucination in AI systems occurs when outputs are generated that may be irrelevant, nonsensical, or incorrect based on the input provided.
In the context of RAG, we can more specifically define hallucination as any response generated by an LLM that is not grounded in or supported by the relevant contextual information retrieved through RAG. Even if the LLM produces a seemingly correct answer, it's considered a hallucination if it wasn't derived from the retrieved context.
RAG is designed to minimize hallucinations by providing the LLM with relevant, up-to-date information for each query. However, hallucinations can still occur if:
The retrieval system fails to find relevant information
The LLM misinterprets or incorrectly applies the retrieved information
The LLM generates content beyond the scope of the retrieved information
It's important to note that while RAG significantly reduces the risk of hallucinations, it doesn't eliminate them entirely. Responses that appear correct but aren't based on retrieved information may stem from the LLM's pre-training, which could be outdated or incorrect.
Despite these measures, users and developers should always be aware that some level of hallucination risk remains in any generative AI system, including those using RAG.
Summarization
Summarization is the ability of generative models to analyze large texts and produce concise, condensed versions that accurately convey the core meaning and key points.
4 main ways to deploy LLMs in enterprise settings
Large language models (LLMs) can be deployed in various ways within enterprise environments, each with its own strengths and limitations. Let's explore the four primary types of deployment: native use, curated content, internet-connected, and curated content with plugins.
1. Native use
Native use refers to employing a large language model exactly as it is trained, without any modifications. This deployment results in ungrounded responses since no information retrieval occurs during response generation. Such deployments are suitable for basic informational queries, learning about general topics, summarizing content, and performing creative tasks like writing simple poems.
 Figure 2: In native use, a user inputs a question, the model processes it to generate a summary, and outputs the response.
Figure 2: In native use, a user inputs a question, the model processes it to generate a summary, and outputs the response.
Native use is generally considered one of the most straightforward deployment methods for generative AI, as this approach involves generating responses based solely on the data the model is trained on. It does not retrieve information from external sources in real-time. Consequently, the information provided by native generative AI models is limited to the knowledge cutoff date of its training data, which can lead to outdated or potentially inaccurate responses as time passes.
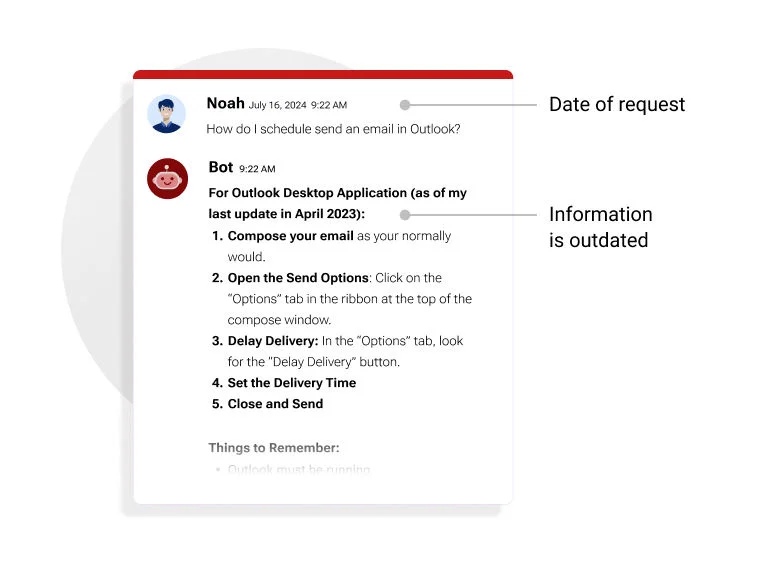 Figure 3: In this context, the native use model is referencing information from one year prior, highlighting potential issues with relevance and accuracy due to outdated data.
Figure 3: In this context, the native use model is referencing information from one year prior, highlighting potential issues with relevance and accuracy due to outdated data.
In real-world applications, these native AI deployments often appear as simple implementations of ChatGPT-like models. Crucially, these systems are not integrated with any information retrieval functionality, meaning they rely solely on their pre-trained knowledge and can't access or utilize up-to-date or organization-specific information.
However, it's important to note that most users interacting with these systems may not realize this limitation. The AI can often provide convincing responses that seem knowledgeable, even without performing any actual information retrieval, leading to a false impression of the system's capabilities.
The key drawback of these native deployments is their inability to answer questions about proprietary or internal organizational content. Since they lack connection to any internal databases or document repositories, they can't provide accurate or current information specific to the organization using them.
2. Incorporating curated content via basic RAG
In this deployment, the model relies on curated internal organizational knowledge and external sources of information.
State-of-the-art systems use advanced search algorithms to find the most pertinent information for each query. These typically include semantic search, which understands the meaning and context of the query, and keyword search, which matches specific words or phrases. Once relevant content is retrieved, the large language model summarizes it to provide a concise, appropriate response to the user's query.
This approach ensures that AI responses are based on current information, respectful of data access permissions, relevant to the specific query, and summarized for easy understanding. Proper implementation of these elements helps create a reliable, secure, and effective AI system that can accurately answer queries based on an organization's proprietary information.
It almost goes without saying that effective data governance and management are critical when implementing any AI system that relie on curated content. It's crucial to keep the information up-to-date, as outdated data can lead to inaccurate or irrelevant AI responses. The system must also respect user permissions, ensuring that responses are based only on content that the user is authorized to access. This protects sensitive information and maintains data security.
 Figure 4: In curated content deployments, the model combines internal and selected external sources to provide up-to-date, well-managed outputs.
Figure 4: In curated content deployments, the model combines internal and selected external sources to provide up-to-date, well-managed outputs.
A benefit of using curated content is that it significantly reduces hallucinations, providing users with accurate responses based on the organization's verified knowledge. However, this approach has a limitation: if a query doesn't match any information in the curated sources, the system won't generate a response. This scenario is often referred to as hitting the “backstop.”
To address this limitation, some consider a hybrid approach. This method primarily uses curated content for responses but falls back on the LLM's general knowledge when no relevant curated information is found. While this seems to offer the best of both worlds, it introduces new challenges.
The main risk of this hybrid approach is the potential for user confusion. When accurate, curated responses are mixed with potentially hallucinated ones, users may struggle to distinguish between them. This can lead to misinformation if users treat all responses as equally reliable.
Another complication arises from the nature of search algorithms. Small variations in how a query is worded can significantly affect search results, meaning that similar questions might yield different responses — one grounded in curated content, another based on the model's general knowledge. These responses could potentially conflict, further confusing users who may not perceive their queries as significantly different.
Given these challenges, the hybrid approach requires careful consideration, as it may not always provide the best of both worlds. While it aims to provide more comprehensive coverage, it may inadvertently introduce inconsistencies and reliability issues. Organizations must weigh the benefits of broader response capabilities against the risks of potential misinformation and user confusion.
3. Connecting to the Internet as a source via RAG
In this faily simple deployment, the LLM receives information retrieved from an internet search. Unlike curated content deployments where data is sourced from specific sources, here the model accesses the open Internet, without the ability to restrict sources to particular websites. This approach ensures responses based on a wide range of available sources but presents several challenges.
Accuracy and reliability are major concerns, as the LLM might pull information from unreliable websites, leading to inaccurate responses. Additionally, information from the open Internet may not align well with the specific needs of the user's organization, lacking contextual relevance. Maintaining consistent quality and style is also difficult when pulling data from various sources, resulting in variable response quality.
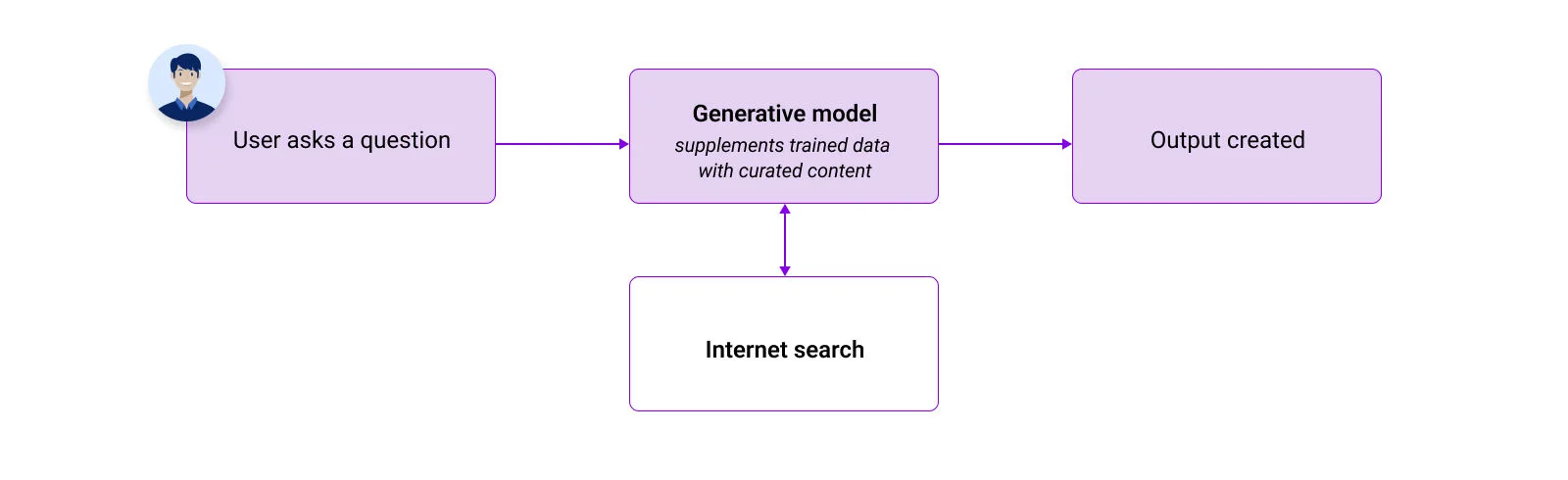 Figure 5: The large language model accesses the internet to retrieve information, providing responses based on open-source data without restrictions to specific websites.
Figure 5: The large language model accesses the internet to retrieve information, providing responses based on open-source data without restrictions to specific websites.
4. Using curated content and plugins via RAG
This approach involves using pre-selected internal or external sources of information and integrating plugins to enhance the capabilities of the LLM. Building upon the curated content deployment mentioned earlier, this approach adds extensibility to support a wider range of use cases beyond simple knowledge search and question answering.
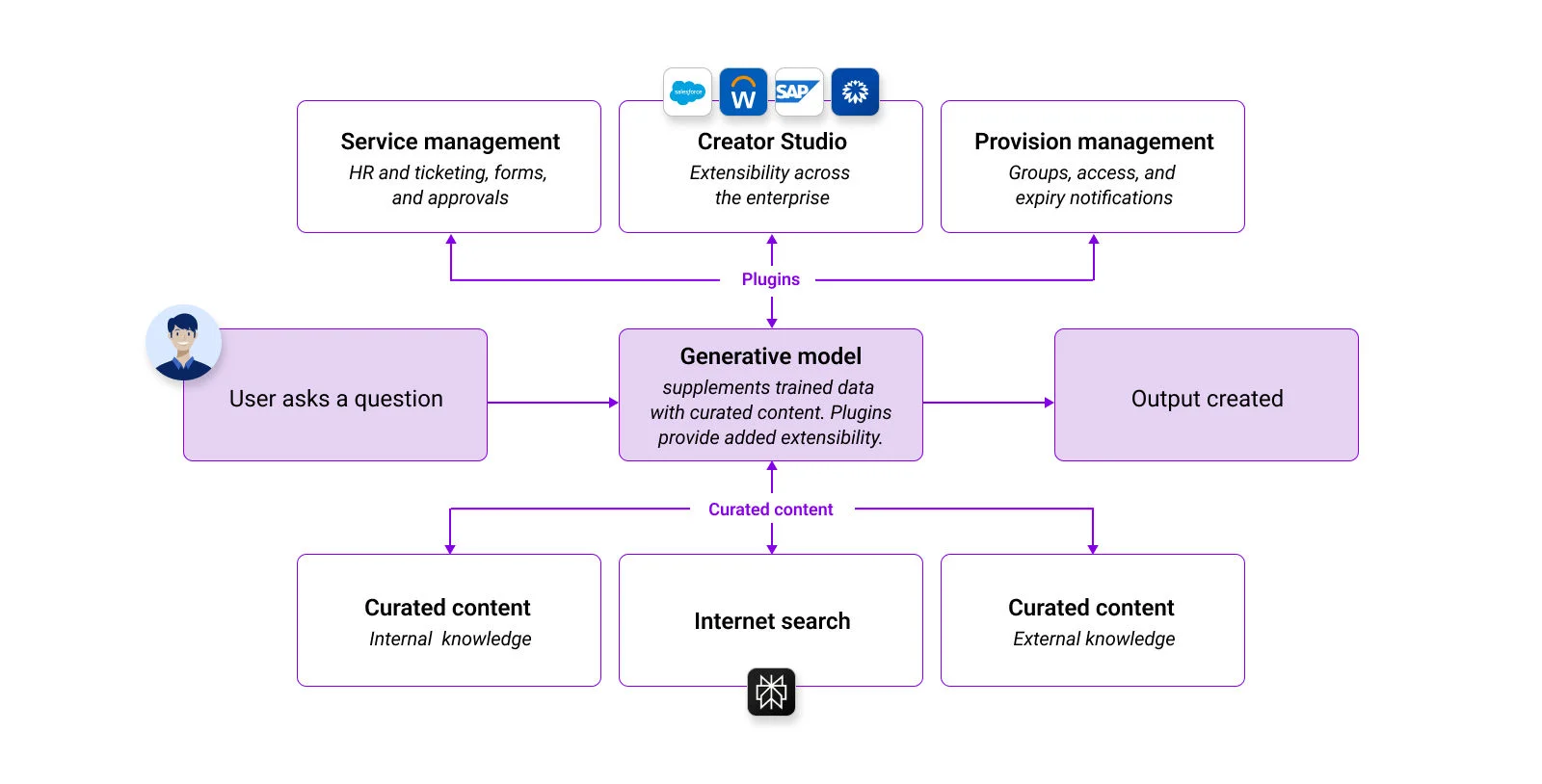 Figure 6: Curated content is enhanced with plugins, allowing for the integration of a variety of use cases beyond simple knowledge retrieval and question answering.
Figure 6: Curated content is enhanced with plugins, allowing for the integration of a variety of use cases beyond simple knowledge retrieval and question answering.
Many current LLM deployments such as this are limited to single-use scenarios or rely on complex decision trees that are difficult to scale, which can hinder their effectiveness and flexibility. However, in the Moveworks Platform, curated content is enhanced with plugins that expand functionality to include both pre-built and custom use cases through Creator Studio.
These plugins are modular components that use agentic AI to analyze user queries and select the most relevant ones to fulfill requests. This seamless integration enables users to perform searches and actions across various platforms such as Salesforce, Workday, ServiceNow, or Coupa using natural conversational language, without needing to understand the underlying systems involved.
 Figure 7: Moveworks Copilot handling diverse tasks. Three examples show: (1) Retrieving Q1 revenue data, (2) Adding a user to a distribution list, and (3) Managing a purchase order. These demonstrate the Copilot's versatility.
Figure 7: Moveworks Copilot handling diverse tasks. Three examples show: (1) Retrieving Q1 revenue data, (2) Adding a user to a distribution list, and (3) Managing a purchase order. These demonstrate the Copilot's versatility.
Moveworks makes generative AI work for the enterprise
Generative AI, particularly through LLMs, holds significant promise for transforming enterprise operations. Understanding how to effectively deploy LLMs, especially with methodologies like retrieval-augmented generation, is crucial for maximizing their impact in business settings. Moveworks stands out as a leader in enterprise AI solutions:
- Expertise: Since 2016, Moveworks has pioneered AI solutions for enterprises, driven by a team of exceptional engineers who live and breathe these challenges. Their deep expertise and relentless pursuit of innovation empower Moveworks to effectively address complex business challenges with precision and agility.
- Comprehensive integration: Our platform seamlessly integrates with a diverse range of curated content sources and applications, ensuring responses are not only accurate but also timely and contextually relevant.
- Advanced capabilities: Moveworks offers a suite of plugins that augment our Copilot's functionality across enterprise systems. These plugins enable natural language interactions, empowering users to perform tasks and retrieve information effortlessly.
- Intelligent automation: By automating plugin selection with agentic AI, Moveworks simplifies workflows and enhances operational efficiency, freeing up valuable resources for more strategic initiatives.
- Enterprise-focused prompting: Our AI solutions are designed with business needs in mind, prioritizing relevance, accuracy, and security in every interaction.
Choosing Moveworks means adopting more than just an AI solution; it's about embracing a platform that evolves with your enterprise. Continuously enhancing productivity and user experience while upholding rigorous standards of data governance and security, Moveworks empowers organizations to thrive in the era of AI-driven digital transformation.
Embracing AI for enterprise transformation
Generative AI, particularly through LLMs, is changing how enterprises operate, promising unprecedented efficiencies and innovation. As businesses increasingly integrate AI into their workflows, understanding how to effectively deploy LLMs becomes paramount. Moveworks, a leader in AI-powered business solutions, stands at the forefront of this evolution.
Focusing on enterprise AI since 2016 and continually advancing with the latest models and techniques, Moveworks empowers enterprises to address complex challenges with agility and precision.
Choosing Moveworks means having a partner committed to continuous innovation and enterprise transformation. Our solutions prioritize accuracy, relevance, and security in every interaction, empowering organizations to thrive in the era of AI-driven digital transformation.
Ready to see how Moveworks can transform your enterprise with AI?
Request a demo today and discover how Moveworks can streamline your operations, boost productivity, and drive innovation across your organization.

