
Table of contents
Moveworks Enterprise Search builds on the latest advancements in generative AI and our years of experience supporting the knowledge needs of millions of employees via the Moveworks platform. We have combined the power of reasoning with the superior user experience provided by Retrieval Augmented Generation (RAG) to transform how employees search for information!
The result is a powerful, versatile solution that aims to solve the challenge of breaking down the barriers between employees and the information they need to get work done.
Recap: What is RAG?
The first large-scale impact of generative AI was ChatGPT, which instantly transformed the experience of answering questions using large language models (LLMs). From a search perspective, one of the first use cases to emerge after this was Retrieval Augmented Generation (RAG). In this architecture, an LLM is connected to a vector-embeddings based retrieval system connected to a data source, or directly to a set of documents, and exposed to the user through a chat interface. The user can then query the underlying sources, and the RAG system provides summaries that are grounded in retrieved data.

This provided many enterprises their first glimpse of effective search in the era of LLMs. RAG made it easy for enterprises to prototype search applications internally. The improvement in quality of coherence and relevance of search results was dramatic over prior keyword-based retrieval systems, which provided a wall of (mostly irrelevant and inscrutable) blue links.
Shortcomings of the RAG architecture for Enterprise Search
RAG with vector embeddings-based retrieval has shown the potential of enterprise search. The ease of getting started has resulted in widespread experimentation with in-house RAG solutions and several successful POCs. But wide adoption has been limited due to several challenges, some of which are related to the RAG architecture itself.
In this blog, we’ll dive deeper into four specific challenges:
1) RAG alone cannot guarantee accuracy
Architecturally, a RAG system does not have any native capabilities around understanding which sources have trustworthy information for various kinds of user queries. An enterprise search solution’s primary success criteria is accuracy of results. What often creates impediments here is diversity of sources of information for similar types of questions.
For example, if a salesperson asks for the revenue on an opportunity, what is a trustworthy source? Chat logs from Teams or Slack, or emails in my inbox, or the business’ CRM?
A RAG system cannot ascertain that a CRM is the most trustworthy source of revenue data. As a result, it may pull updates from an email and potentially mislead an employee.
This is further exacerbated by RAG’s inability to decide what is truly important in the data it does retrieve. As a result, while the responses may appear to be phrased eloquently or naturally, they leave a lot to be desired when it comes to their precision and usefulness.
2) Hallucinations are common with RAG systems
Hallucinations are an inherent property of LLMs. The superpower of LLMs is natural and realistic language generation, but it is also their Achilles heel if not addressed properly. When an LLM is asked to summarize content, it can make up information or distort facts while appearing coherent and persuasive.
Grounding, or the process of generating text by providing content to summarize, is necessary but nowhere sufficient to prevent hallucinations. Grounding alone cannot overcome the limitation that RAG systems don’t have any architectural capabilities that can impose truthfulness in their results.
3) RAG does not understand unique business context
Every business uses internal jargon and acronyms. RAG systems don’t naturally have any awareness of business context, and as a result, this jargon is sometimes handled as keywords, or worse, spell-corrected by LLMs when they are retrieving and summarizing information. For a user, this causes the quality of results to degrade, especially when they are looking for business-specific information and insights.
4) RAG does not automatically handle scale
Enterprise search needs to handle a large volume and variety of data. Companies often have terabytes to petabytes of data within billions of files, documents, and business objects. Unless there is an intelligent way to retrieve the most relevant documents for summarization, RAG struggles with making sense of the volume and variety of data that a naive retriever produces.
Agentic RAG brings intelligence to RAG
This set of diverse challenges cannot be solved by relying on basic RAG systems, which will fail at the very first hurdle of enterprise-wide scale. In fact, we need to rethink enterprise search - it is not enough to be a simplistic way to retrieve and summarize information. Instead, it needs to be a dynamic, intelligent and goal-oriented system which autonomously navigates the complexity of information and data and enables the user to get accurate and trustworthy results. That’s where agentic RAG comes in.
Agentic RAG combines the strengths of Retrieval-Augmented Generation and AI Agents to incorporate autonomous reasoning and decision making as part of finding relevant information. This approach allows for managing complex tasks across diverse and extensive datasets.
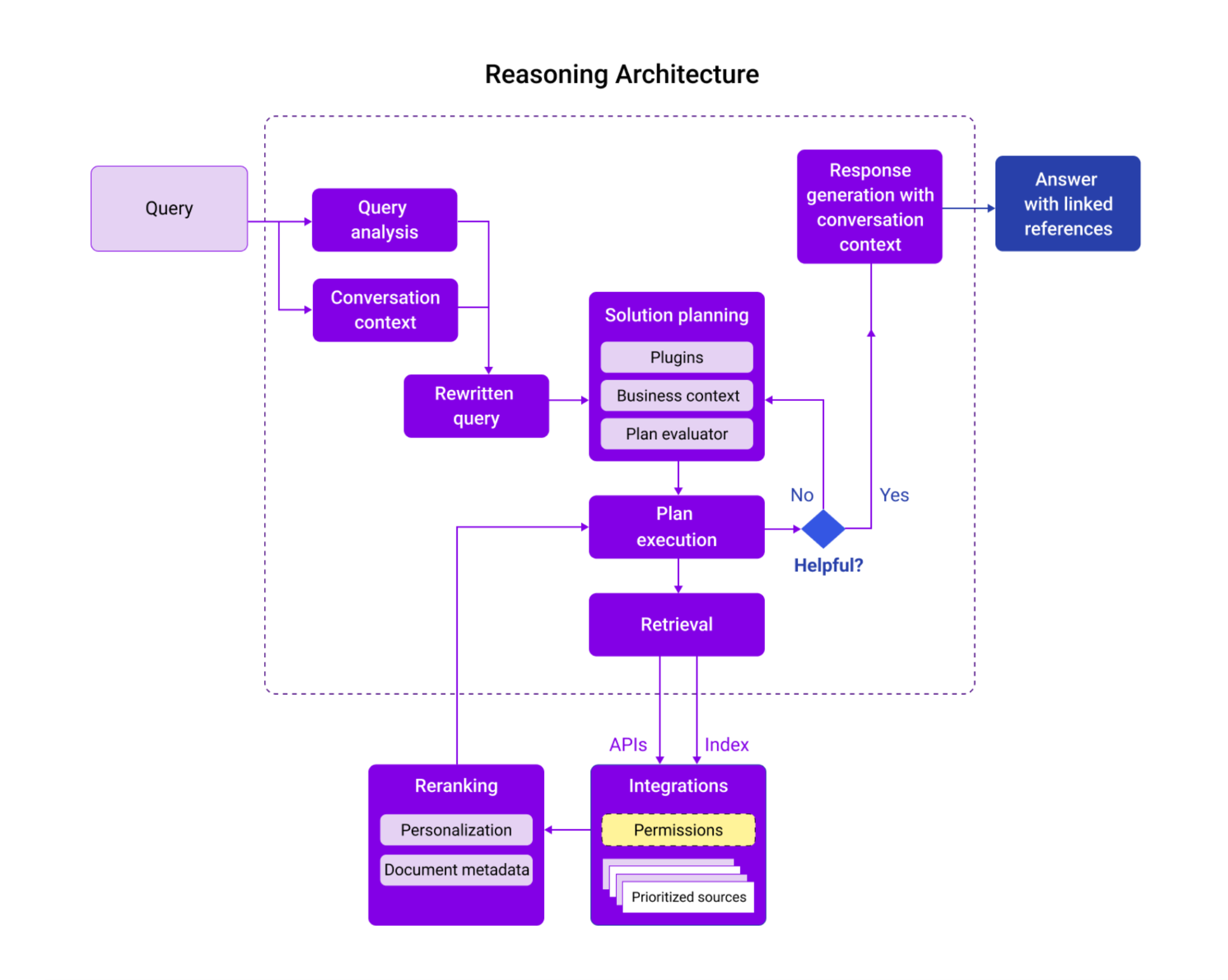
Agentic RAG is able to offer these benefits by performing the following key steps for every request:
- Query enrichment and rephrasing: The Agentic RAG system autonomously interprets the intent of the query and rewrites or rephrases it to make it complete and increase the odds of finding relevant content across different systems. It also adds conversation context and business context such as entity information to incorporate signals that are unique to each organization.
- Why this matters: Helps to ensure that the query is well-specified and includes org-specific business context and terminology.
- Reasoning and approach planning: An agentic system connected to multiple data sources can break down complex queries into smaller sub-tasks and independently create a plan to use the tools or plugins at its disposal for each step. This is critical for queries where some actions or pre-processing is needed to create a high-performing query to search with.
- Why this matters: Enables complex queries to be answered by breaking down the query into logical steps and ensuring that the appropriate source is used for each step.
- Intelligent retrieval and ranking: The system combines results retrieved from each content source queried and produces a high-quality ranked list of resources that prioritizes the right mix of systems and content types. These are based on the user’s query and personalization signals such as the user’s role and location, as well as document signals such as recency and source authority.
- Why this matters: Identify the highest confidence results from the prioritized sources with personalization of results to improve relevance.
- Goal-oriented summarization with references: Based on the query intent and the ranked results, the summarization autonomously applies judgment on the utility of results to incorporate relevant content and presents them in a concise, easy to consume format. Most importantly, it provides references to the source content inline to enable the user to verify the resources, if they wish. It also informs the user when high-confidence results are not available, maintaining rigor in the quality of the results.
- Why this matters: Provides the user with a response that can be easily verified to increase the trust between the system and the user.
As we can see, there are several decisions being made in real-time, which is only possible with an agentic architecture capable of adapting and deconstructing the query, selecting from multiple tools, planning a multi-step approach, incorporating a variety of contexts and producing responses that are tailored to the type of query.
Here’s a quick summary of all the ways in which Agentic RAG outperforms basic RAG:
Agentic RAG | Basic RAG | |
Use of context | Incorporates business and conversation context to adapt the query and improve success of downstream steps | Limited contextual awareness |
Approach planning for complex queries | Breaks down complex queries into multiple sub-tasks and creates a plan to execute the plan | No multi-step reasoning |
Select the appropriate tools based on query | Selects from and uses multiple tools autonomously in real time | Decision making is minimal and mostly static or heuristic based |
Personalization of results | Incorporates user context to identify the most relevant results | Basic personalization through prompts which is not reliable |
Discretion in source and content selection in responses | Uses the content authority and confidence of the results to select relevant sources and tailor a response that best answers the query | Static rules and prompts determine retrieval and response generation |
Referenceability and trustworthiness | Provides inline references for the user to verify the truthfulness of the summary to underlying data. | No references provided |
Delivering on this new way forward with agentic RAG can unlock significant upside for employees. Specifically:
- Answers that are up-to-date and accurate
- Answers that are personalized at scale
- Answers so hyper-relevant that they help to drive ubiquitous adoption of enterprise search
Introducing Moveworks Enterprise Search with Agentic RAG
Moveworks Enterprise Search leverages agentic AI to deliver the trustworthy and accurate answers that employees are actually looking for.
Moveworks is introducing a new approach to enterprise search by enhancing RAG with reasoning. It leverages a powerful Reasoning Engine that’s able to understand employee goals, develop intelligent plans, and search across various business systems to return top-quality search results. With our entry into the enterprise search category, we’re delivering on the promise of agentic RAG, and more. Here’s how:
- Citations presence that makes every effort to fact-check for accuracy and link to citations where possible to help to solve for the distortion of information through hallucination.
- Over 100+ connectors that integrate to connect Moveworks Enterprise Search to the most useful information repositories, as well as a way to add custom use cases for information retrieval from any system of record.
- Granular permissions & access controls to enable the right employees to have access to the right information (and nothing more).
- Data volume and variety. Moveworks Enterprise Search scales to support the large data volumes and variety of business objects that are commonplace in the enterprise.
- Robust analytics to enable stakeholders stay in the loop on adoption as well as usage, and make data-driven decisions on how to continuously improve the overall state of service for employees.
Together, these features form the basis of a solution that’s enterprise-ready from Day 1. Our platform delivers the reliability, scalability, and security demands of organizations today.
It’s time to take search to the next level. Break free from obsolete, basic RAG and jump aboard enterprise search powered by agentic RAG with Moveworks Enterprise Search.
Want to learn more about the power of Enterprise Search? Learn more about our solution at our virtual live event on November 12 at 10AM PT.

