Table of contents
Since ChatGPT burst onto the scene, large language models (LLMs) have been making waves in the business world, capturing the attention of everyone from tech titans to ambitious startups. It should come as no surprise, then, that the market is flooded with a vast array of LLM solutions.
With this constant release of new models from companies like OpenAI and Google, one thing is abundantly clear to us at Moveworks: LLMs will not be one-size-fits-all.
Pinpointing the right AI solution for your specific needs requires a clear understanding of each model's capabilities and limitations. And while existing benchmark studies might provide useful insights, they don’t focus on an LLM’s performance in the enterprise environment.
That’s why our team dedicated itself to developing a benchmark explicitly addressing the needs of enterprises. This way, we can offer a more targeted evaluation, guiding leaders so that they can select the AI solution that truly aligns with their objectives.
Today, we’re going to break down the results, explaining:
- The existing benchmarks for evaluating large language models
- The challenges of using existing language model benchmarks for the enterprise
- The details of the Moveworks Enterprise LLM Benchmark
- The results of the Moveworks Enterprise LLM Benchmark
- Key takeaways
Long story short: A fine-tuned LLM excels in enterprise tasks compared with larger out-of-the-box models
The results of the Moveworks Enterprise LLM Benchmark demonstrate that LLMs fine-tuned on the enterprise dataset surpassed their larger counterparts.
GPT models demonstrate impressive reasoning capabilities as well as capabilities to learn from in-context examples. However, in enterprise settings, models have to deal with enterprise-specific jargon and knowledge not available in the generic knowledge encapsulated in public LLMs.
Furthermore, in enterprise settings, LLMs are used as a component of a larger system. So, in many cases, the outputs of LLM are expected to be in a structured format that another system can understand. For example, Moveworks uses structured JSON as a canonical output format for span extraction tasks.
One can teach LLMs to handle enterprise-specific knowledge and produce structured output by providing in-context examples in the prompt. However, from our experiments, we have found that LLMs fine-tuned on enterprise-specific tasks and a corpus can understand enterprise-specific language and excel in enterprise-specific tasks as well as a GPT model — even when the model size is 10X smaller!
The key takeaway is that while GPT-class models possess immense power and will undoubtedly play a central role in various AI applications, task-specific models are more reliable than off-the-shelf alternatives.
Current large language model benchmarks
As language models become increasingly essential, establishing accurate performance evaluations is vital. Emerging evaluation resources, such as Stanford's Holistic Evaluation of Language Models (HELM) and EleutherAI's LM Evaluation Harness, offer comprehensive frameworks to examine the latest LLMs across various tasks. By employing these evaluative measures, researchers can better understand LLM abilities and drive improvements in the rapidly evolving field of language processing.
For example, two popular benchmarks for testing LLMs like OpenAI’s GPT-4, Databricks’ Dolly, and Facebook’s LLaMA are the AI2 Reasoning Challenge (ARC) and WinoGrande. The ARC dataset includes a collection of 7,787 science exam questions in English multiple-choice format and plays a significant role in assessing language models' reasoning capabilities. On the other hand, the WinoGrande dataset is rooted in the WSC, a set of 273 expert-crafted pronoun resolution problems developed to challenge statistical models that rely on word associations or selectional preferences.
These open-source datasets evaluate LLMs' capabilities, especially their zero-shot performance: the ability to adapt and perform well in new, previously unencountered real-world situations without tailor-made training.
Challenges of using existing language model benchmarks for the enterprise
While existing LLM benchmarks serve as valuable resources, there are several issues that arise when using them for enterprise-specific applications. There are three main challenges:
- Lack of enterprise specificity
Many existing benchmarks, such as the ARC-e dataset, focus on general knowledge questions. For instance, a question like "Which factor will most likely cause a person to develop a fever?" is crucial for evaluating a general LLM. However, it may not provide relevant insights for an enterprise-specific LLM that caters to specialized tasks, like asking where a certain conference room is or requesting a software application.
- Stagnant datasets
Most existing datasets are not routinely updated, making it challenging to evaluate advanced and continuously improving LLMs accurately. And as newer LLMs achieve increasingly higher scores, making meaningful comparisons among them becomes problematic.
- Latest LLMs outperforming benchmarks
The latest LLMs, such as GPT-4, have achieved remarkable scores on popular benchmarks such as ARC and WinoGrande (with GPT-4 scoring 96.3% on ARC and 87.5% on WinoGrande). These high scores highlight the evolving sophistication of LLMs, and the current benchmarks may no longer effectively capture their complete capabilities.
Even within our own experiments of understanding these models, we have observed instances where LLM outputs do not match the human evaluation labels. Still, these outputs provide better or more accurate answers. This phenomenon illustrates that advanced LLMs can potentially contribute to refining benchmarks by correcting errors in human evaluation labels and improving the overall formatting of existing datasets.
In light of these challenges, developing newer benchmarks that can cater explicitly to enterprise-specific requirements, accommodate the rapid advancements in LLM technology, and provide a more accurate and nuanced comparison between different models is essential. By addressing these concerns, enterprises can more effectively harness the power of LLMs to drive their specific use cases and needs.
Introducing the Moveworks Enterprise LLM Benchmark
To accurately gauge the performance of various LLMs in enterprise applications, we created the Moveworks Enterprise LLM Benchmark.
At Moveworks, our engineering and in-house annotation teams put a lot of effort into gathering and organizing data specific to the corporate world, including enterprise support tickets, enterprise knowledge, and of course, conversations between employees and their Moveworks bots.
This data was used to evaluate different LLMs so that we could pick the best ones to use. To make this evaluation process efficient, our machine learning engineers converted the data into an easy-to-follow format consisting of instructions and examples of input and output, known as instruction-input-output trios.
We created 14 tasks focusing on essential themes of enterprise use cases — generation, reasoning, relevance, extraction, and classification — with zero-shot to long context inputs, such as the complete enterprise email support ticket. We will continue to add more tasks as we progress in creating a more comprehensive enterprise LLM benchmark.
Which models did we test?
To ensure a comprehensive assessment, we focused on our proprietary dataset of enterprise tasks for benchmarking. We analyzed several models' performance, including models such as GPT-3.5 Turbo, GPT-4, and MoveLM™ — Moveworks' own proprietary LLM that we're currently building and testing and that will be available across our entire platform in the coming months. These models are instruction-tuned on internal and external datasets to optimize the model's performance on enterprise-specific tasks. The internal Moveworks dataset is a set of 70K instructions generated from enterprise use cases.
Base model name | Base model developed by | Already instruction-tuned? | Fine-tuned on internal dataset (Moveworks) | Model parameter |
GPT-3.5 Turbo (ChatGPT) | OpenAI | ✅ | - | - |
GPT-4 | ✅ | - | - | |
GPT-J | EleutherAI | - | - | 6B |
GPT-J Fine-tuned | - | ✅ | 6B | |
StableLM Base | Stability AI | - | - | 7B |
StableLM Fine-tuned | - | ✅ | 7B | |
StableLM OpenAssistant | ✅ | - | 7B | |
Dolly | Databricks | ✅ | - | 7B |
Dolly Fine-tuned | ✅ | ✅ | 7B | |
MPT Instruct | MosaicML | ✅ | - | 7B |
MPT Fine-tuned | ✅ | ✅ | 7B |
Table 1: Overview of models tested in the Moveworks Enterprise LLM Benchmark
Despite countless other impressive fine-tuned models, we narrowed our focus to prevent an overwhelming rundown in this blog post. With our test setup, we sought to challenge the limits of LLMs by posing questions specifically tailored to the enterprise environment. By placing these models in situations they had not previously encountered, we aimed to evaluate their ability to rapidly generate accurate and relevant responses under pressure, similar to “thinking on their feet.”
The results of the Moveworks Enterprise LLM Benchmark
Let’s dive into some results of the Benchmark assessment.
Ticket closing comment helpfulness classification
Identifying helpful ticket comments is critical in understanding the resolution of common issues that arise in enterprise settings. A significant portion of enterprise issues is resolved via tickets. Ticket content, along with its comments, provides extremely useful information about enterprise issues.
However, many ticket comments are not helpful. Comments like “Closing this ticket” or “Issue has been resolved” do not provide helpful information about resolving the issue. We use AI models to identify ticket-closing comments that include valuable information on how to resolve a specific issue. This information is then used to better understand our users' problems in enterprise settings.
The subtlety of "helpfulness" can be challenging to navigate. For instance, when an IT agent resolves an issue with Microsoft Business Central and comments, "Business Central is now working again from links within Workday," it indicates the problem has been fixed. Still, it doesn't provide enough information on how to resolve the issue in the long term.
Consider the following example cases:

In above example, closing comment — while curt — does include resolution steps on how to update the disk. GPT-3.5 Turbo's output is false, incorrectly identifying the comment as unhelpful. However, MoveLM correctly identifies the comment as helpful, providing the true output.
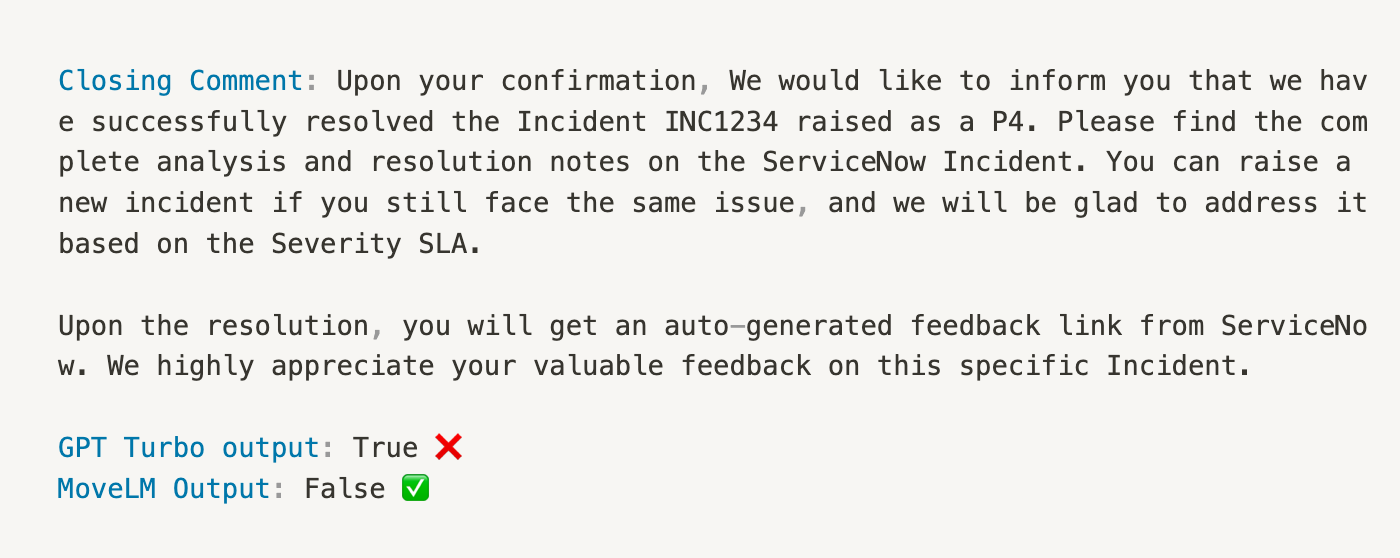
In this instance, while the comment is long, it does not include detailed steps for resolution. GPT-3.5 Turbo's output is True, wrongly classifying the comment as helpful. But MoveLM accurately identifies the comment as unhelpful, returning the true output.
The examples demonstrate MoveLM's capability to discern helpful comments, which contributes to a better understanding and resolution of user issues in enterprise environments.
 Figure 1: Even though was a zero-shot experiment, MoveLM performed better against few-shot experiments with competing models featured in this benchmark.
Figure 1: Even though was a zero-shot experiment, MoveLM performed better against few-shot experiments with competing models featured in this benchmark.
Stakeholder analytics intent classification
At Moveworks, we maintain a fine-grained intent taxonomy covering pairs of actions and resource types that span the entire breadth of enterprise support issues across IT, HR, Finance, Legal domains, and beyond. Our detailed understanding of enterprise intent allows us to provide prescriptive analytics through our flagship data product, Employee Experience Insights (EXI).
Within EXI, we maintain a simplified version of our intent taxonomy that leaders at organizations easily understand, called BART (Business Action Resource Taxonomy). This taxonomy classifies all tickets at an organization into a two-dimensional grid based on the tickets’ action and resource type. At a glance, this shows enterprise leaders a holistic view of the state of tickets across their organization and allows them to drill down into specific hotspots to improve the employee experience.
With our corpus of 500 million enterprise support tickets at Moveworks, our LLMs are fine-tuned on high-quality samples from this corpus and are able to extract nuances that off-the-shelf models do not easily capture.

The above example demonstrates intent classification in the case of a ticket submitted to request a specific form. MoveLM model accurately labels the ticket as Provision, signifying that the requested document needs to be shared with the user. On the other hand, GPT-4 marks the same ticket as Manage, failing to recognize the enterprise context.
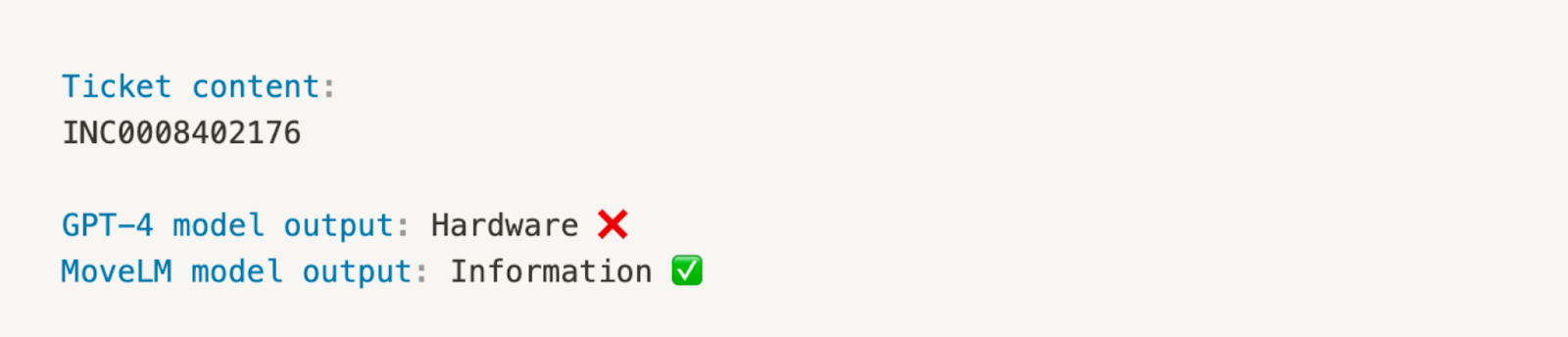
Additionally, in cases where a ticket refers to a pre-existing ticket, the fine-tuned MoveLM™ model can correctly classify the ticket as Information. In contrast, GPT-4, without proper context, may inaccurately label the ticket as Hardware, further highlighting the advantage of training LLMs on a corpus of enterprise support tickets.
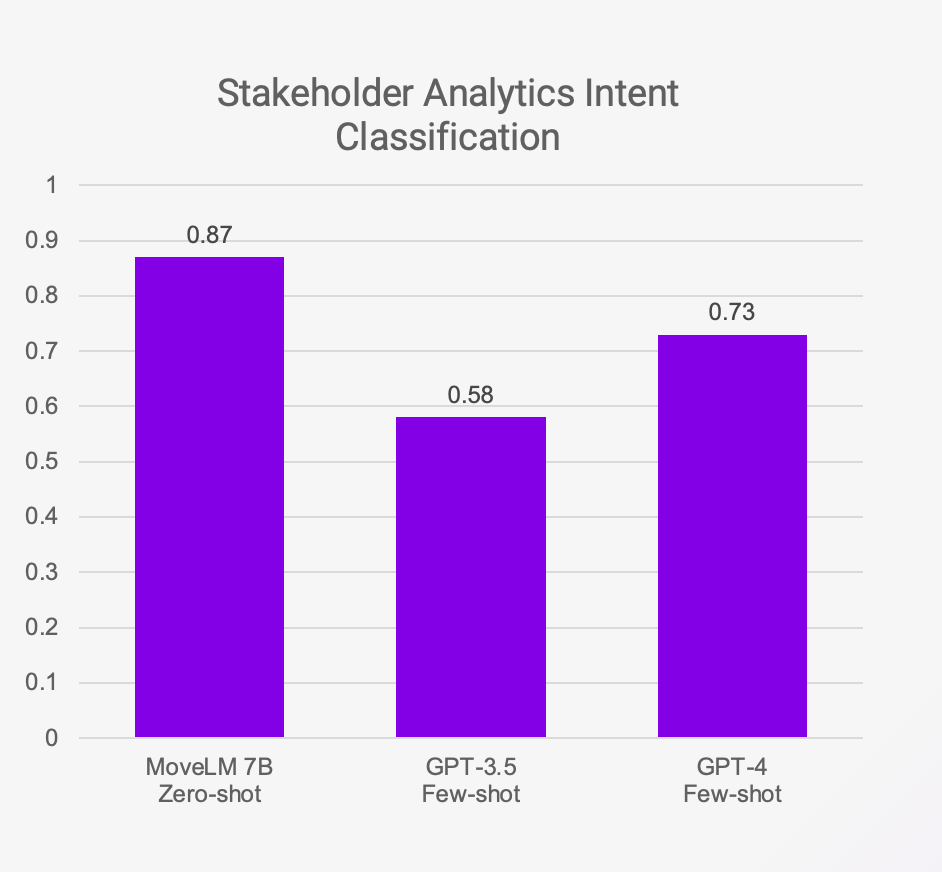 Figure 2: Even though was a zero-shot experiment, MoveLM performed better against few-shot experiments with competing models featured in this benchmark.
Figure 2: Even though was a zero-shot experiment, MoveLM performed better against few-shot experiments with competing models featured in this benchmark.
Generating API calls from natural language
Enterprises use and integrate with many systems to organize and manage workflows. Such integrations enable seamless communication and data exchange between different software systems, thus allowing for enhanced efficiency and improved collaboration across other business processes.
At Moveworks, we help our customers automate these mundane and time-consuming processes to unlock their full potential by enabling them to interact with such systems with a conversational interface without worrying about the technical nitty-gritty.
An essential aspect of building such a solution is to be able to predict what system contains the information that a user wants to access and how to retrieve that information from that system. Our models leverage the vast amount of diverse user requests made in the past and the corresponding actions to better understand user queries and handle complex language nuances, thus providing more accurate and contextually relevant responses.
Consider two examples where users submit requests to Moveworks:

In the above example, given the query "What's Moveworks ARR?" MoveLM successfully understands the user's request and is able to generate an API call given a list of API’s and its descriptions in context. On the other hand, the GPT-4 model incorrectly responds, saying that it doesn't have an API to answer the query.

The example above demonstrates how fine-tuned MoveLM is able to understand enterprise specific context. In this case, the GPT-4 model does not understand from context that ‘Clover’ is a on-site location and mistakenly responds by attempting to retrieve the customer profile for Clover. On the other hand, the MoveLM model correctly identifies the context of the query and fetches site information about Clover, demonstrating its superior understanding of user intent and language subtleties.
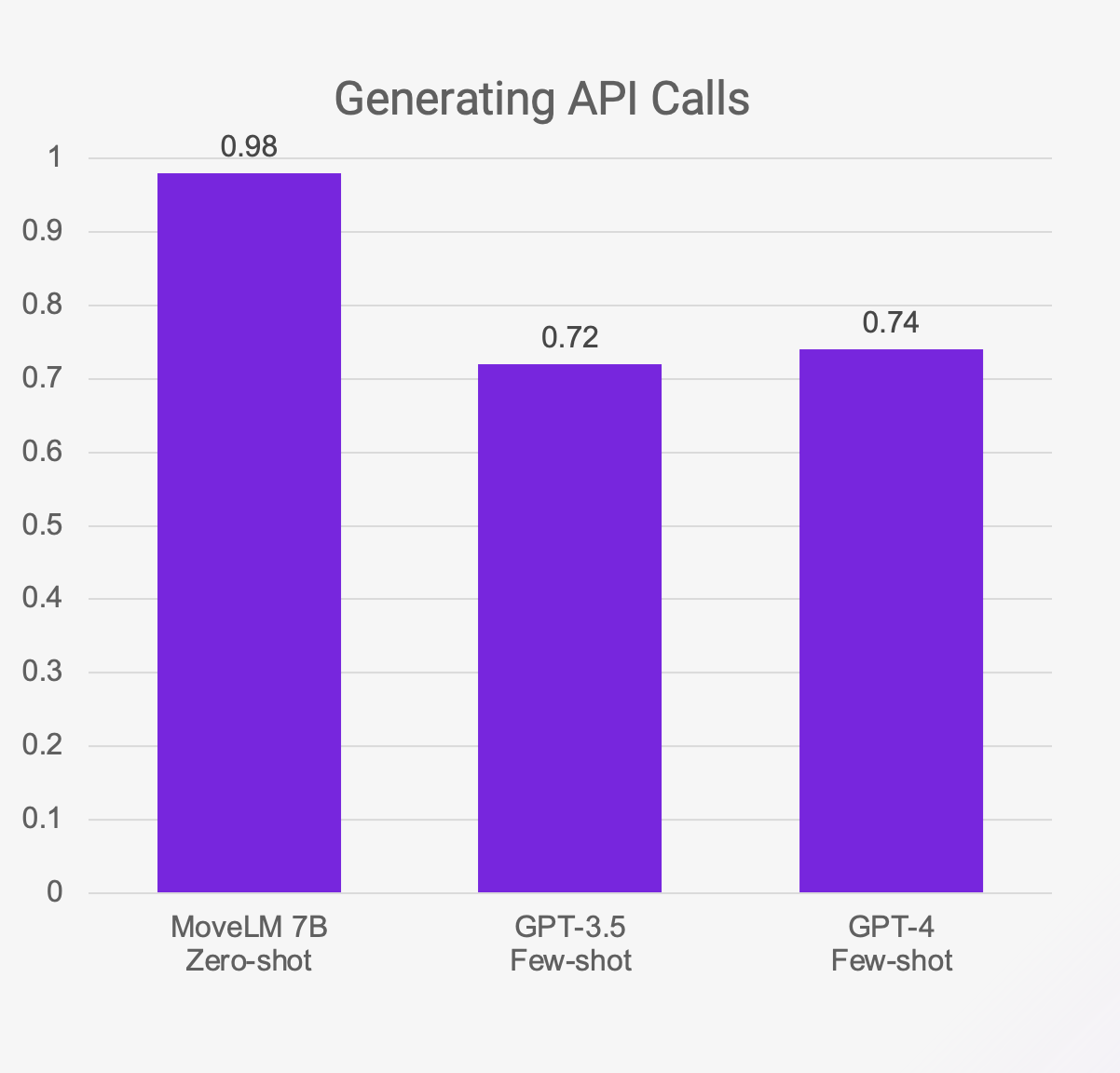 Figure 1: Even though was a zero-shot experiment, MoveLM performed better against few-shot experiments with competing models featured in this benchmark.
Figure 1: Even though was a zero-shot experiment, MoveLM performed better against few-shot experiments with competing models featured in this benchmark.
Key takeaways of the Moveworks Enterprise LLM Benchmark
We hope that the discussion above drives home the point that LLMs are not going to meet the needs of enterprise AI right out of the box. Observing the qualitative examples above and performance on our Enterprise Benchmark, we are seeing that fine-tuning on high-quality data is necessary. This results in superior performance, but more importantly, reaching a performance level essential for generative AI to be useful in enterprise workflows.
Enterprise AI needs models to be performant on accuracy, latency, customizability, and operating cost. We show that our much smaller MoveLM 7B almost consistently outperforms out-of-the-box LLMs on enterprise tasks for all these dimensions.
Model | ||||||
Task Type | Best 6B/7B OOTB Model Few-shot | MoveLM 7B Zero-shot | GPT-3.5 Turbo Zero-shot | GPT-3.5 Turbo Few-shot | GPT-4 Zero-shot | GPT-4 Few-shot |
Relevance - internal dataset | 0.33 | 0.93 | 0.84 | 0.84 | 0.92 | 0.95 |
Extraction - structured output for queries | 0.38 | 0.98 | 0.22 | 0.72 | 0.38 | 0.73 |
Reasoning - custom triggering | 0.62 | 0.93 | 0.87 | 0.88 | 0.9 | 0.88 |
Classification - domain of user query | 0.21 | 0.79 | 0.6 | 0.73 | 0.7 | 0.76 |
Extraction - structured output from entity typing | 0.83 | 0.87 | 0.9 | 0.89 | 0.89 | 0.89 |
Classification - intent for analytics | 0.22 | 0.87 | 0.58 | 0.58 | 0.55 | 0.64 |
Relevance - forms | 0.61 | 0.95 | 0.65 | 0.73 | 0.64 | 0.89 |
Classification - intent for conversation | 0.12 | 0.72 | 0.68 | 0.69 | 0.7 | 0.72 |
Classification - people look-up | 0.78 | 0.99 | 0.54 | 0.61 | 0.9 | 0.93 |
Extraction - structured output for slot filling (F1 Score) | 0.18 | 0.77 | 0.13 | 0.44 | 0.15 | 0.50 |
Classification - ticket closing comments helpfulness | 0.52 | 0.9 | 0.45 | 0.64 | 0.67 | 0.73 |
* All metrics are variants of exact-match accuracy unless mentioned otherwise. Higher values are better.
Through extensive iteration on data curation and model fine-tuning, we discovered that we can unlock even more potential by overlaying a task-specific, company-specific adapter on top of our enterprise foundation LM. The table above highlights the impressive performance of our newly-developed language model: MoveLM.
Moving forward, we are eager to explore the incredible possibilities of fine-tuning with high-quality data in the realm of enterprise AI. Our next steps focus on three fundamental aspects:
- Factuality via context-grounded instruction data generation to help the model learn the enterprise context
- Customizability through task-specific parameter efficient fine-tuning (PEFT) to achieve optimal results for each unique task
- Alignment by employing reinforcement learning with human feedback (RLHF) to ensure the model is closely aligned with enterprise processes.
With these advancements in play, we are confident that we are well on our way to unveiling the true power of enterprise artificial intelligence, pushing the boundaries of what was once thought impossible to achieve in the rapidly-evolving world of AI technology. Stay tuned as we continue on this journey to unlock the full potential of AI for the enterprise!
Contact Moveworks to learn how AI can supercharge your workforce's productivity.


